

Introduction
Il sonne hyper prétentieux ce titre. Je veux dire, plus que d'habitude.
Avant, PHP, c'était comme mes titres: sans prétention, libre, flexible, ouvert, une porte vers un nouveau monde de développement d'applications.
Aujourd'hui, qu'est-ce que c'est PHP? Un langage qui passe obligatoirement par un de ces FRAMEWORKS modernes, "propres", avec un système de gestion de dépendance et sujet de conventions et de stickers qu'on colle sur son MacBook Pro (à savoir qu'afficher un sticker PHP c'est un peu comme dire à tout le monde que vous allez à des concerts de flûte à bec - pas de jugement mais bon voilà, quoi).
En toute innocence, Je voulais vous montrer comment assembler une application PHP avec une structure moderne, des composants modernes, une gestion de ressources statiques par Webpack, et le style de code que vous voulez, sans frameworks.
Et vous savez quoi? C'est beaucoup plus rapide comme ça. Et je vais vous le prouver.
J'ai le logo PHP qui traîne sur ma page ENGAGEZ-MOI (n'allez pas voir elle craint cette page) — Il est temps de le prouver (rires).
Je suis vieux
PHP c'est tellement de bons souvenirs. Ce n'est pas juste un langage de programmation, c'est un phénomène en terme d'accessibilité à créer des applications web avec une facilité extrème.
Et ce même en sachant qu'à l'époque, il fallait utiliser un programme comme EasyPHP pour facilement tester ses développements sous Windows. A vrai dire je suis un peu épaté que le projet coure toujours, je pensais qu'il était remplacé par les serveurs de dev inclus avec les frameworks, Docker, ou encore XAMPP (qui est plus ou moins la même chose que EasyPHP en fait?).
Et justement ça fait partie de mes demandes pour la base de développement que je veux vous présenter: il faut pouvoir fournir un moyen de tester l'application sans devoir installer ou configurer un bidule comme XAMPP. Parce que je trouve ça sale.
A la limite tester avec une machine virtuelle (avec Vagrant ou une recette Ansible pour l'installation) ou Docker est plus élégant, mais ce serait-y pas encore mieux de pouvoir tester avec juste PHP d'installé? Oui, moi je trouve que c'est mieux.
Bon, revenons aux trucs de vieux: qui se souvient de PHPNuke? Leur page Wikipedia anglophone est assez comique.
Pour son clan Counter Strike c'était difficile d'avoir plus la classe qu'avec ce type de présentation:
L'âge d'or du MVC
L'avantage de PHP, outre qu'il était bien plus accessible que .NET et son Visual Studio/Windows Server payant (et vachement cher aussi, même si vous utilisiez Visual Basic qui est probablement universellement considéré comme pire langage que PHP, ce qui est un exploit à part entière), c'est que l'on peut facilement bourrer du code PHP (et donc du code serveur) au milieu du code HTML.
En effet, PHP était supposé être un "préprocesseur" juste avant le HTML. Aujourd'hui c'est un peu plus que ça puisqu'on peut s'en servir comme langage de script ou bien pour envoyer un résultat qui n'est pas du tout du HTML. Mais à la base, on écrit du PHP au milieu d'horrible code HTML bourré de <table> et de <marquee>.
Les concepts de base du protocole HTTP sont tout autant digérés et régurgités, alors que dans d'autres langages il faut se battre avec des concepts de requête et de réponse.
Dans l'article sur mes origines d'artiste, je parle de cours de développement web:
Le candidat idéal pour la productivité artistique ce sont par exemples les travaux pratiques sur le développement web. Le prof se casse après avoir suggéré d'installer EasyPHP et lire Wikipedia (expérience vécue) - reste plus qu'à créer une page dégueulasse style:
<html>
<head></head>
<body>
<?php echo $_POST['lol'] ?>
<br />
<form method="POST" action="#">
<input type="text" name="lol" />
<input type="submit" value="MLDSFKJD" />
</form>
<body>
</html>Quand on apprenait le PHP c'était ce genre de truc qu'on faisait.
Un peu plus tard arrivera le concept de Séparation du code présentation et logique dit aussi SEPARATION OF CONCERNS - Et qui s'enchasse dans la mode connexe du MVC - le fameux Model/View/Controller.
Si vous vouliez être pris au sérieux avec votre framework il fallait qu'il suive le paradigme MVC. En pratique ce paradigme est un peu tout moisi. C'est comme une religion qui vous oblige à aller écouter un sermon tous les jours à base de gens morts, de prépuces et de terre promise et vous dites à tout le monde que vous faites toujours partie de cette religion mais vous n'allez secrètement pas au sermon.
Pour le MVC, c'est pareil. La logique des vues et des contrôleurs, en particulier, est tellement étroitement liée que vous pouvez piéger n'importe qui en lui demandant "mais donc ça, c'est du code vue ou contrôleur?" — question idéale pour entretien d'embauche des années 2000.
En pratique, Laravel et Symfony suivent toujours le paradigme MVC. Moi je vais juste plus ou moins le suivre à savoir que la séparation contrôleur et vues sera à définir à votre convenance, et le modèle vous le mettez où vous voulez.
Si quelqu'un fronce les sourcils quand vous lui expliquez que vous travaillez de cette manière, parlez-lui simplement de React et du JSX et vous devriez être tranquilles. Il y a moulte ressources en ligne pour préparer votre débat.
$_GET, $_POST et tout ça
PHP nous donne accès à ces magnifiques variables (globales (= SATAN EN SHORT aujourd'hui)) qui reprennent automagiquement les valeurs qui ont été postées via un formulaire ou les valeurs qui sont dans sous forme de "query" dans l'URL. Par exemple cette mangnifique URL:
http://monsupersite.com/accueil.php?module=news&id=15Nous donne accès à:
echo $_GET['module']; // "news"
echo $_GET['id']; // "15"Avec d'autres informations comme l'adresse IP du client ou l'user agent se trouvant dans encore une autre globale appelée $_SERVER.
Rien que cet aspect du langage ça pue le vieux grenier. Qui utilise sérieusement des URL avec ?machin=truc? Il y a eu une brève période où on utilisait toujours ça au travers de réécritures d'URL que personne ne comprenait, mais maintenant c'est terminé. Fini les URL moches.
Je dois dire que cet aspect là je suis plutôt pour. Genre totalement pour.
Un peu dans le même genre, $_POST est légèrement désuet. D'abord il fonctionne avec des données encodées dans le corps de la requête avec le vieil encodage valeur=truc. Je ne sais pas si je dois vous rappeler qu'on est dans l'age d'or du JavaScript et que vous êtes supposés tout faire en JSON.
Eventuellement, si vous avez besoin d'un formulaire de contact, OK, pourquoi pas.
Apparemment la dernière fois que j'ai du en pondre un en 5 minutes j'ai tout de même supposé qu'on allait recevoir du JSON et n'utilise même pas $_POST.
Tout ça pour dire que c'est une bonne choses que certains aspects moisis de PHP soient un peu décédés et que je n'ai aucune intention de les déterrer.
L'âge d'or du CMS
Je ne me vois pas parler du bon vieux temps et ne pas évoquer tous ces projets PHP qui se faisaient pirater tous les trois jours et qui vous envoient une bonne pelletée de spam via votre formulaire de contact Wordpress qui a pourtant un captcha plus ou moins à jour.

Projets open source de l'ère pré-Github, cette section vous est dédiée. Il y a fort à parier que sans l'accessibilité et la flexibilité de PHP, ces projets n'auraient jamais vu le jour et vous n'auriez pas pu rencontrer tous ces chouettes gens sur ce fameux forum de passionnés d'images paisibles et rassurantes pour bien faire dodo.
Ne pas oublier son histoire, c'est important. J'ai décidé de faire un talbeau parce que j'utilise jamais de tableau.
| Projet | Type | Description |
|---|---|---|
| Wordpress | CMS/Blog | Cible perpétuelle d'attaques. Demande le mot de passe FTP de ton hosting (lol) — pays du spam en commentaire et sur formulaire de contact; Connu pour ses "thèmes" qui incluent 15 imports JavaScript et 10 imports CSS séparés — Moteur de milliards de blogs décédés à leur naissance avec juste un vieux "Mon premier post lel" qui traine depuis 2011 |
| phpBB | Forum | Pouvait aussi être étendu pour en faire tout un CMS - Connu pour être horrible sur mobile et aussi pour les inscriptions automatiques journalières de robots russes qui essayent de poster du spam |
| PhpMyAdmin | Gestion de DB | Pour une raison que je n'explique pas vraiment, une grande quantité de devs veulent absolument ce truc pour gérer leur DB MySQL. Cible numéro 1 d'énormément d'attaques pusique peut potentiellement vous fournir accès aux DBs et les robopirates sont particulièrement intéressés par la DB de votre blog qui a deux visites par an — Moche, surtout sur mobile |
| Joomla | CMS | Le bon vieux temps. Prenez un thème Joomla quelque part, collez-le sur votre hosting partagé à 2€/mois qui est un peu lent parce qu'il envoie secrètement 10000 spams par heure en arrière-plan, et vous avez quelque chose à vendre à votre client pour au moins 600€ — Connu pour sa favicon très reconnaissable (surtout pour les pirates je pense) |
| PostNuke | CMS | J'avais juste envie de vous montrer cette page — Ca me donne envie de pleurer tellement c'est beau. Signe de modernité en tant que successeur de PHPNuke, le thème n'utilise pas de <table>, si c'est pas magnifique. |
| Drupal | CMS | Drupal était vu comme un truc mieux que Joomla. Plus modulaire, plus pour experts quoi. En pratique c'est tellement modulaire qu'il faut ajouter toutes sortes de couches de caches de BLOCKS, 10000 divs partout sur la page et toujours les 1000 fichiers JS et CSS à importer dans votre thème (qui est moche et non-responsive) |
| MediaWiki | Wiki | PHP ça nous ramène aussi aux WIKIs, je suis obligé d'en parler. Je m'étonne toujours que dans les demandes de dons au sommets des pages Wikipedia, ils ne mentionnent pas quelque chose du genre "vous savez on tourne sous PHP et MySQL... Et ouais" — Parce que ça pourrait motiver davantage de dons |
Qu'on se le dise tout de suite, utiliser un CMS PHP en 2019 c'est la grosse loose. Non seulement c'est bien lent au niveau PHP même avec de multiples niveaux de cache obscurs, mais en plus CSS et JavaScript ne sont pas du tout optimisés et au niveau sécurité c'est une catastrophe qui demande des mises-à-jour constantes pour éviter de se faire spammer toutes les demi-heures.
"Oui mais avec le CMS mon client peut modifier lui-même ses pages!" — Est-ce que votre client a déjà modifié lui-même ses pages? Genre une seule fois? Non? C'est bien ce que je pensais. Réfléchissez avant de parler la prochaine fois, on est sur mon blog, mes opinions sont 100% correctes avec 0% d'incertitude.
Pour ça, Laravel et Symfony c'est bien. Parce qu'on est dans un réel artisanat. Et si vous avez besoin de permettre une modification de quelque chose, vous l'implémentez vous-mêmes de A à Z, c'est pas bien compliqué.
D'où vient la réputation douteuse de PHP?
Certains vous diront que c'est le langage lui-même qui manque d'élégance, est trop permissif ou euh... Ouais je pense que c'est à peu près tout ce que les gens peuvent dire de plus ou moins légitime.
Selon moi la mauvaise réputation de PHP ne vient pas de là. Au contraire, l'accessibilité du langage est, à mon sens, une force. Si vous n'êtes pas d'accord, ben vous êtes pas d'accord.
Je vais vous dire ce qui, je pense, est la souce de tous les maux: le modèle d'exécution. La manière dont l'interpréteur PHP s'enchasse avec le serveur HTTP, comment ça fonctionne quoi.
Le modèle d'exécution en PHP est assez unique en son genre en cela qu'il s'agit presque toujours de faire en sorte qu'un serveur HTTP appelle un CGI externe pour gérer le code PHP (ou un truc vaguement équivalent, on va faire simple, hein). Le CGI appelle à son tour l'interpréteur, qui exécute le code de bout en bout, puis retourne le résultat, qui est repassé au serveur HTTP, et la boucle est bouclée.
Vous êtes peut-être en train de vous demander ce qu'il y a d'hors norme là dedans, surtout si vous utilisez exclusivement PHP.
Je me rends compte que c'est pas du tout clair cette histoire, je pense que je vais pas y couper, je vais devoir faire peter paint et dessiner un truc sale. Mieux! Je vais plutôt prendre en photo des dessins infâmes que j'ai fait dans un cahier avec un stylo bille qui bave.
Voilà comment se passerait une requête type pour un fichier PHP qui s'appelle fichier.php (typique, quoi) et qui affiche juste "salut":
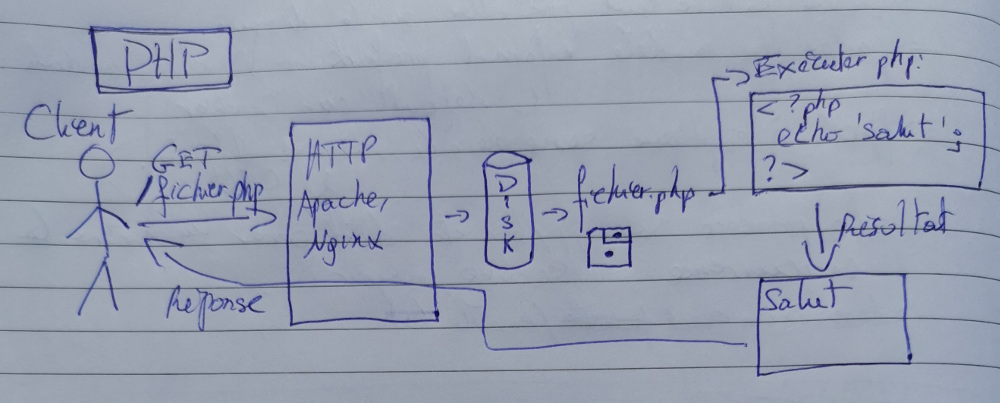
En fait je suis pas sûr que ça soit plus clair... Le problème c'est que c'est impossible à expliquer sans supposer que vous ayez certaines bases en protocole HTTP et connexes ainsi qu'en systèmes d'exploitation.
Je vais quand même vous expliquer comment ça se passe:
- Le client demande la ressource "/fichier.php" au serveur HTTP (peut-être qu'il a demandé "/machin" et qu'une règle de réecriture change ça en "/fichier.php" derrière, je simplifie n'est-ce pas)
- Le serveur HTTP (Apache ou Nginx, par exemple) a un "handler" configuré pour PHP, c'est à dire qu'il passe le fichier dans une moulinette spéciale dont la sauce interne peut varier — pour faire simple disons qu'il invoque l'interpréteur PHP sur le fichier
- L'interpréteur lit le fichier de haut en bas, importe ce qu'il doit importer, exécute ce qu'il doit exécuter, puis quand il a fini, ben, il a fini et toutes les ressources qu'il utilisait sont immédiatement libérées comme si un process s'arrêtait
- Pendant ce temps le résultat (la réponse) est diffusé(e) vers le client, puis c'est fini
Alors oui, il faut aller chercher physiquement le fichier PHP concerné qui peut lui-même faire des include, require ou autres et provoquer la lecture d'encore plus de fichiers .php.
Cet aspect est la raison pour laquelle le cache d'éxécution (opcache) est important mais aussi pourquoi avoir ses fichiers PHP dans un ramdisk peut-être une bonne idée. Mais je m'emporte.
Intéressons-nous à comment ça se passerait pour un autre type de technologie backend, comme... Genre, toutes les autres technologies backend qui ne sont pas Visual Basic sur ASP.NET version 1.0 — c'est-à-dire que des technologies comme Python (à noter que Python utilise un modèle un peu différent en général mais passons ce détail), Java ou encore Node.JS vont tous démarrer et conserver un processus en mémoire, qui est votre application.
Complétons le schéma:
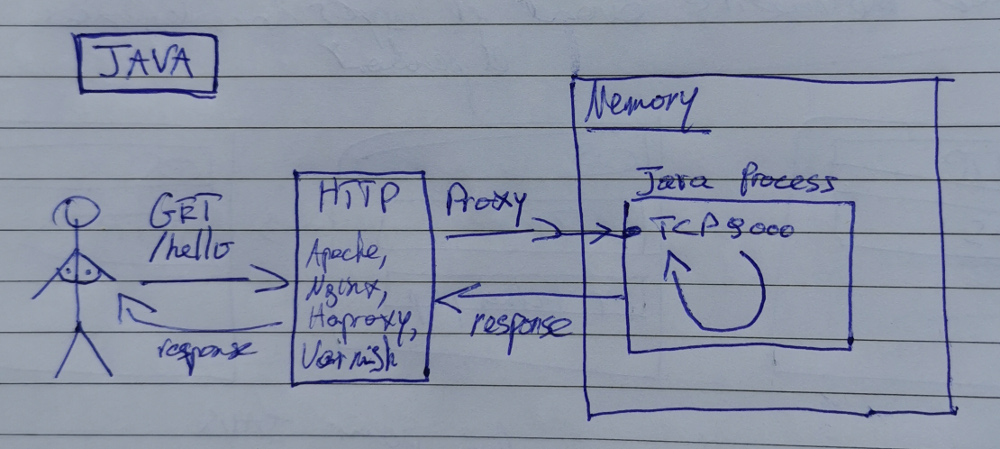
C'est à nouveau simplifié et il y a plus d'une manière d'arriver à cette fin. Oui, je sais qu'on pourrait même se passer du serveur HTTP dans ce cas précis. Du calme.
- Le client fait une requête sur /hello
- Ce chemin de requête, ce nom de domaine ou autre caractéristique, est configuré sur le serveur HTTP pour mener à une requête mandataire (PROXY en français dégeulasse) vers le processus de notre application qui est résident en mémoire, et écoute sur le port TCP 9000 en HTTP
- Ce processus a sa propre soupe interne de comment-il-va-gérer-plusieurs-requêtes-en-même-temps (il pourrait même ne gérer qu'une requête à la fois, pourquoi pas hein), nous on s'en fout, il nous renvoie sa réponse
- Le serveur HTTP transmet la réponse au client
Vous avez compris la différence? Non?
Vous avez de la chance j'ai préparé d'autres dessins hyper convaincants pour montrer ce qu'il se passe en mémoire:
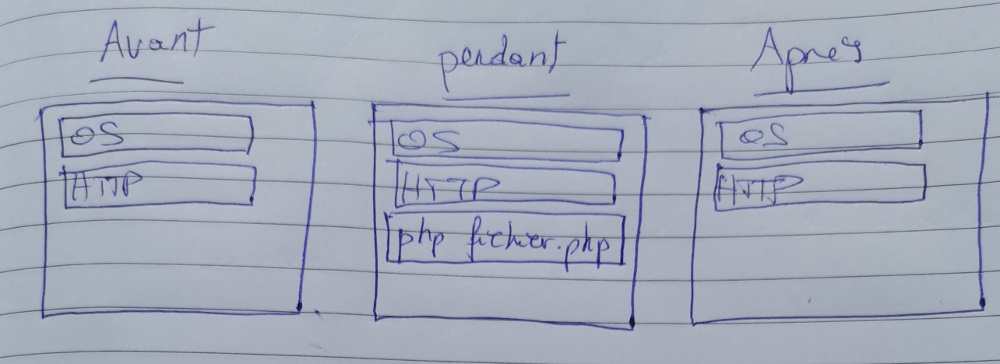
Le serveur HTTP est tout le temps présent en mémoire. Parce que sinon, ben ça marche pas, quoi. J'explique bien, hein?
Au moment où on a besoin d'exécuter une requête PHP, on invoque l'interpréteur qui crée tout son contexte en mémoire le temps de son exécution. Puis, quand il a fini (de préférence un jour il doit finir — il y a un temps limite configurable) il s'arrête comme n'importe quelle autre processus qui s'arrête, et le système d'exploitation peut entièrement récupérer la mémoire qu'il utilisait.
Pour Java c'est un peu différent:
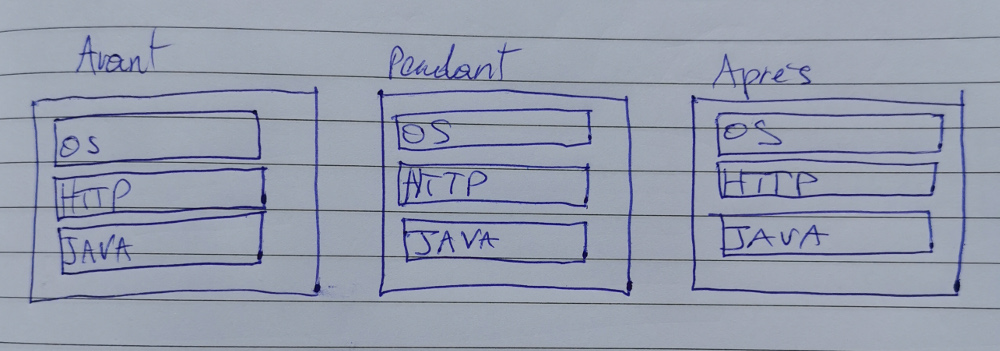
Et euh... Là on voit bien (???) que notre application est représentée par un (ou plusieurs dans certains cas mais disons un) processus qui restent tout le temps en mémoire.
Il est là avant la requête. Il est là pour répondre à la requête. Quand la requête est terminée il est toujours là.
Quand ce processus a démarré, il a peut-être chargé toutes sortes de ressources externes, comme un script PHP aurait pu le faire, mais comme notre processus est toujours là après la requête... Il a pu conserver ces ressources et ne dois pas les recharger à la prochaine requête. PHP doit tout recharger à chaque requête.
Oui, toutes ces explications c'était pour mener à cette conclusion. Génial.
Vous l'avez donc compris (lol), PHP ne garde rien en mémoire alors que pour une app. Spring Boot Java vous avez un process "java" qui correspond à l'application. Avec ExpressJS vous avez un process "node" quelque part dans votre mémoire.
Conserver un processus résident en mémoire a quelques avantages directs: vous pouvez ouvrir quelques connexions à des bases de données d'avance (concept du connection pool, impossible à réaliser avec PHP seul), conserver des structures de cache en mémoire, garder certains fichiers ouverts et verrouillés tout le temps pour ne pas avoir à les rouvrir chaque fois, et surtout, comme mentionné précédemment, tout ce qui est "initialisation" (lecture de config, chargement du code, etc.) se fait une seule fois au démarrage du process.
Avec PHP... Ca se passe à CHAQUE REQUÊTE. Et pas juste l'initialisation, tout le bordel se passe à chaque requête: les connexions DB, les ouvertures de fichier, les lectures et écriture de structures de cache qui ne peuvent pas être en mémoire, etc.
Cela étant, il est courant de coller certaines autres projets sur PHP pour servir de sparadrap. Par exemple, Redis et Memcache sont des souvent couplés avec PHP pour pouvoir justement conserver des information en mémoire entre les requêtes.
Certains vous diront peut-être que l'on est pas censés conserver tout plein de trucs dans le processus résident d'une application Java, NodeJS, Go, etc. Moi je vous dirais, d'après ce que j'ai vu en pratique, tout le monde s'en fout x10000, et puis de toute manière, si vous pensez que vous avez besoin de Redis pour votre appli, ben... Allez-y, c'est pas réservé uniquement au PHP.
Quoi qu'il en soit, on a tendance à oublier que Redis implique de parler à un socket d'une manière ou d'une autre, et c'est une opération bloquante au niveau CPU. Alors, certes, c'est très rapide (surtout avec un réseau correct ou un process local), mais multipliez ça par un usage ultra intensif et vous verrez qu'il y a bel et bien un prix à payer.
Récapitulons les petits soucis architecturaux de PHP:
- Ne peut pas conserver de contexte global ou d'information en mémoire qui puisse être réutilisé entre les requêtes client
- Pas de connection pooling pour les bases de données
- Tout ce qui concerne des opérations asynchrones complexes (qui ne sont pas juste lire un fichier) est très difficile à faire efficacement — C'est une des raisons pour lesquelles les applications PHP sont souvents accompagnées de batches à lancer en ligne de commande
- La configuration, l'initialisation des classes, du code, des variables et zones mémoires, les imports de librairies, les connexions DB, etc. doivent être répétés pour chaque requête client
A force d'avoir appuyé sur le gros bouton blanc j'espère que vous aurez compris que ce dernier point est, selon moi, la source de mauvaise réputation de PHP et de la plupart de ses maux, en tous cas du point de vue des gens ouverts et raisonnables (comme moi, quoi).
Opcache et les extensions natives qu'utilisent PHP permettent de limiter la casse mais le modèle d'exécution reste extrêmement inefficace.
PHP c'est complètement pourri alors?
Ne pas conserver un processus en mémoire a tout de même quelques avantages:
- Votre application est pratiquement immunisée aux fuites mémoire (le serveur HTTP et son gestionnaire de bidules pour exécuter PHP ne le sont pas, mais c'est censé être du logiciel très stable)
- Etant donné que tout est très isolé par conception, PHP s'arrange naturellement bien en scaling horizontal — c'est-à-dire ajouter plusieurs serveurs ou conteneurs en load balancing
- Pas de problèmes liés aux threads (race conditions, etc.)
- Possibilité de déploiement à chaud (dit aussi à l'arrache) — Il n'y a aucun service à redémarrer, vous pouvez simplement mettre à jour votre code depuis git, par exemple, et hop, ça marche sans downtime (si votre code n'est pas tout pourri); c'est un avantage non négligeable pour des petits développements
- Votre application ne peut pas planter — Je veux dire par là que si un processus PHP individuel plante, ça n'a pas d'impact direct sur les requêtes qui suivent (normalement :D); A noter que le serveur HTTP et ses bidules de gestion d'exécution PHP peuvent planter, eux (mais comme dit au premier point c'est censé être du logiciel stable)
Notons bien pour le dernier point que dans le cas d'une application Go, NodeJS, Java, etc., si le processus de l'application plante, ça ne fonctionne plus du tout. Il s'agit dès lors de mettre en place des systèmes de relance automatique (merci systemd) ou du monitoring. Ces éléments ne sont pas nécessairement obligatoires pour une application PHP.
Toujours est-il qu'à grande échelle, une application PHP souffrira toujours de l'inefficacité de son modèle d'exécution et, même si elle est facile à mettre à l'échelle sur plusieurs systèmes, ça n'est pas sans encourir d'autres complications (gestion des sessions, particulièrement) et surtout, des coûts d'infrastructure qui augmentent.
Ce problème est exacerbé par le modèle d'exécution d'Apache (serveur HTTP, je précise au cas-où) le plus souvent couplé avec PHP, qui est, selon moi, totalement absurde.
Bon là, on y coupe pas, on va devoir aborder certaines notions de système d'exploitation: Une application qui doit gérer plusieurs connexions simultanées ou des opérations bloquantes en général doit avoir un genre de stratégie pour le permettre.
Une des stratégies les plus communes consiste à créer des threads, un par client. Ces "mini-processus" prennent peu de place en mémoire et sont contrôlés par le processus maitre, tout en étant (en général) orchestrés par le système d'exploitation pour ce qui est de décider de comment les ordonnancer. Le modèle threadé est très populaire en Java.
Depuis quelques temps on préfère utiliser un modèle plus économique qui est un peu plus compliqué à expliquer et utilise une sauce de multiplexage et autres appels sytème qui permettent d'attendre certains évènements spécifiques, et tant que ces évènements ne se produisent pas on continue une boucle de traitement tout en gérant une sorte de file d'attente.
Ce modèle n'a, pour simplifier (et souvent en pratique aussi), qu'un seul processus et aucun thread. Il est extrêmement efficace en terme d'utilisation mémoire et CPU puisqu'il ne faut pas échanger les contextes mémoires de 2500 threads toutes les 2 secondes.
C'est ce qu'on appelle parfois l'event loop ou boucle évènementielle, parfois agrémenté du terme "asyncio".
On ne va pas rentrer dans tous les détails mais il va de soi que le modèle threadé et le modèle évènementielle ont chacun des avantages et inconvénients mais le monde semble de plus en plus se tourner vers le mode évènementiel (mode par défaut pour un serveur Apache moderne sans PHP).
Tout ça c'est chouette mais en fait il y a encore un autre modèle d'exécution, celui qu'on garde normalement tout au fond de la cabane de jardin derrière une montagne de trucs oubliés et quelques momies: le prefork.
Son nom vient d'un appel système, fork, qui permet de dupliquer entièrement un processus. Si vous vous demandez en quoi c'est différent d'un thread, c'est que vous suivez parce que ça peut être très similaire selon la manière dont le système d'exploitation gère les threads. Mais, en pratique, une duplication de processus est lente et consomme beaucoup plus de mémoire qu'un thread.
Effectivement, même si le système d'exploitation peut essayer de gérer certaines pages mémoire identiques, il s'agit normalement de copier l'entièreté de la mémoire du processus. Genre, tout.
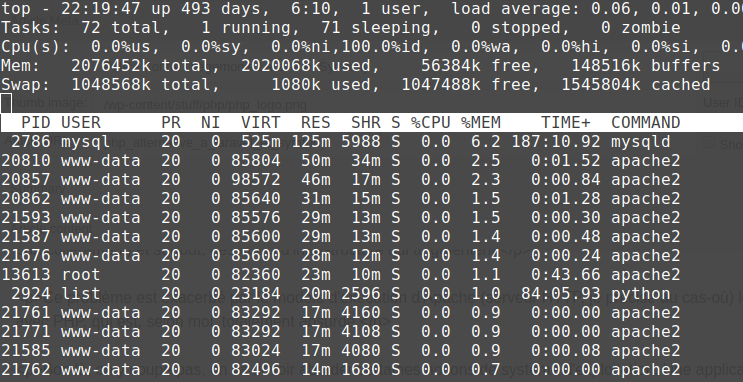
Par conséquent, utiliser Apache en mode prefork, c'est un peu comme si vous lanciez un serveur Apache par client qui va se connecter à vos applications. Je n'exagère même pas. J'aimerais bien être en train d'exagérer là, cet horrible modèle prefork est un cauchemar pour tout admin système qui se respecte.
Et vous savez quoi? Quand on installe PHP et un serveur HTTP sur une distribution Linux, encore à l'heure actuelle, il active le mode prefork.
Même l'image Docker officielle PHP+Apache qui est sur le hub utilise ce mode. C'est bien pratique de pouvoir mettre en place de l'auto-scaling avec Kubernetes pour votre bidule PHP mais s'il a besoin de 6GB de RAM pour gérer 30 personnes ça risque d'auto-scaler sévère et votre portefeuille va auto-scaler de concert.
La solution à ça est d'essayer de coller PHP en mode FPM mais là on sort du cadre de cet article.
Moi je voulais juste vous rassurer que PHP c'était pas totalement moisi. Je sais pas si j'ai réussi. On fait comme on peut hein.
Tout ceci devrait également vous sensibiliser à avoir une étape d'initialisation la plus rapide possible, et donc d'avoir le moins possible d'import de sources PHP et de code PHP à interpréter à chaque requête. C'est la motivation principale du projet qui nous occupe.
Architecture de notre "framework"
Faut le dire vite framework, c'est plus du boilerplate comme on dit chez nous. Ce qui n'est pas si différent de certains projets qui s'étiquettent framework mais sont en fait juste du boilerplate. Je m'égare déjà.
L'année dernière j'avais utilisé le "micro-framework" de Symfony (Silex) qui a désormais été abandonné avec une mention "Utilisez Symfony et faites pas chier".
J'ignore si la même chose est arrivée à celui de Laravel.
L'idée derrière le terme "micro-framework" c'était de réduire le nombre de dépendances et le code d'initialisation tant que possible, et moi je trouvais que c'était une bonne idée.
Raison de plus pour motiver le projet qui concerne cet article.
Récapitulons ce que j'aimerais bien avoir:
- Le moins possible de dépendances
- Pouvoir compacter, minifier et organiser le contenu statique
- Avoir un genre de serveur de dev facile à lancer et avec le moins possible de dépendances
Le contenu statique
J'ignore comment ça se dit exactement en français... Ce que je voudrais faire c'est du static assets bundling, c'est-à-dire compacter, minifier, et mettre ensembles mes ressources JavaScript et CSS, en particulier (d'autres ressources peuvent également être gérées).
En attendant la généralisation d'HTTP 2, compacter les dépendances de vos vues en le moins de fichiers possibles a un impact clairement mesurable sur les performances.
De plus, ça nous apporte d'autres facilités comme la possibilité d'utiliser SASS pour écrire les feuilles de style.
Ces fonctionnalités ne sont pas (encore) offertes par défaut par Symfony ou Laravel, il faut bidouiller avec des modules additionnels et autres complications.
D'autres projets, comme .NET core, ont l'air d'avoir compris l'importance de cet aspect et fournissent des facilités natives pour compiler le contenu statique.
Je trouve personnellement qu'avoir un moyen de compiler son contenu statique est indispensable aujourd'hui et devrais dès lors faire partie du package de base. Cela fait partie des raisons qui me poussent à ne pas utiliser Laravel ou Symfony.
Nous, on va utiliser Webpack.
Je ne suis pas vraiment fan de Webpack, c'est probablement le truc que j'ai eu le plus de mal à apprendre dans le monde JS, et sa configuration dilate tellement les sinus jusque Uranus que des gens ont créé un bundler sans fichier de config en réaction.
Du coup je ne suis pas marié à Webpack et je ne vais jamais prétendre comprendre exactement tout ce que je fais dans sa config ni tous les bugs bizarres qui vous pourrez rencontrer si vous décidez de le mettre à jour (laule) mais là, en gardant ma sale config de base, ça fera déjà le taf de manière stable.
Voici quelques autres avantages que l'on gagne à utiliser un module bundler:
- Pre et post-processeurs CSS
- Modules JavaScript: On peut utiliser npm (joie), importer et exporter librement du code façon NodeJS
- Minification du JavaScript et CSS en production
- Caching du contenu statique et cache busting (vos fichier statiques changent de noms quand ils sont modifiés, de sorte que les utilisateurs vont toujours télécharger immédiatement leur dernière version et ne jamais avoir d'inconsistance due à une vieille version d'un fichier qui serait en cache dans leur navigateur)
- Vous pouvez facilement récupérer des ressources qui seront insérées automatiquement en ligne dans vos fichiers statiques, comme importer du code HTML ou des petits images
- C'est très facile de faire du code splitting (expliqué plus loin)
Puisqu'on se coltine npm, autant l'utiliser comme outil pour démarrer le serveur de dev et contruire le contenu statique pour la version production.
Nous reviendrons au contenu statique plus tard pour son implémentation dans le projet.
Et si je ne veux vraiment pas de module bundler?
Ce n'est pas un problème. Les fichiers statiques sont importés dans les partiels que l'on utilise pour nos vues. Il suffit juste de remplacer les lignes qui chargent ces fichiers (tags <script> et <link>) pour charger vos propres fichiers.
Attention ces fichiers devront être disponibles dans le répertoire public. La structure du projet sera détaillée plus loin.
Gestion de dépendance
Il y a des gens qui ont peur des araignées, moi j'ai peur des systèmes de gestion de dépendance.
J'ai peur de lancer la commande d'installation. J'ai peur de lancer des commandes de mise-à-jour. J'ai peur de ne pas toujours avoir un accès à Internet qui soit en plus capable de télécharger 150 MiO de dépendances juste pour pouvoir accéder à une DB.
Les frameworks PHP utilisent Composer, qui agit comme gestionnaire de dépendance pour les addons des frameworks et certaines librairies PHP.
Si je peux, je préfère totalement éviter de l'utiliser.
C'est pas que Composer est pourri, c'est juste que même quand je travaille avec Symfony, je l'utilise extrêmement rarement pour ajouter des dépendances.
J'avoue qu'avoir un mécanisme d'autoload c'est séduisant. Mais je pense que l'autoloader est un des principaux responsables du fossé de performances que l'on mesurera plus loin entre Symfony et mon projet.
Donc on va éviter.
PHP dispose d'énormément de fonctionnalités directement disponibles au niveau du langage là où, avec Node.JS il aurait fallu installer un module externe pour simplement sortir un hash sha1.
De plus, les fonctionnalités comme les pilotes de base de données sont générallement compilés en tant qu'extensions PHP et pas en tant que packages, et ne sont donc pas installés via Composer.
Là, si vous avez suivi, vous vous dites peut-être "Hey mais attends une minute, tu utilises npm!" — Oui... Je n'en suis pas particulièrement heureux mais je crains qu'il s'agisse d'une nécessité pour les outils de gestion de notre contenu statique.
Le point positif c'est qu'on a accès à l'immensité de l'écosystème JavaScript qui inclut également de quoi faire des TESTS avec ou sans utilisation d'un faux navigateur (entre autres choses) et les tests c'est important il paraît.
Si vous faites un petit peu de JavaScript à niveau semi-sérieux, vous avez de toutes manières absolument besoin de npm puisque, comme je le disais plus haut, JavaScript a très vite besoin de ressources externes.
A vrai dire pour Symfony je trouve le nombre de dépendances "de base" surprenant.
Télécharger le projet
Si vous souhaitez explorer de manière approfondie les sections qui vont suivre, je vous conseille de télécharger ou cloner le dépot des sources du projet.
Je suis au courant qu'il s'agit d'un fork, c'est moi qui ait écrit l'original.
Une version résumée des explications de cet article est présente (en anglais) dans README.md. J'aurais peut-être pas dû le dire... Trop tard vous avez fermé cet onglet. Pas grave j'ai déjà reçu mon chéque pour toutes les pubs que je fais tourner sur mon site.
Structure du projet
Cette structure ne devrait pas vous surprendre si vous êtes familiers avec un des frameworks PHP.
L'idée de base consiste à exposer un seul répertoire au niveau du serveur HTTP, et avoir tous nos fichiers source un niveau en deça et dès lors non accessibles par requêtes directes au serveur HTTP (mais PHP pourra y accéder).
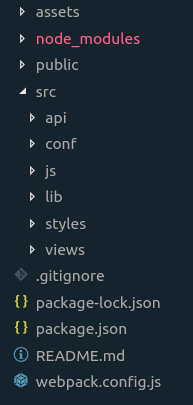
J'ai choisi d'appeler ce répertoire public mais j'ai d'autres projets où il s'appelle web. Vous voyez le principe.
On va aller un peu plus loin en faisant en sorte qu'absolument toutes nos requêtes passent par un point d'entrée unique (index.php) — ce point-là est extrêment courant en architecture d'applications PHP avec ou sans framework.
A la racine du projet nous trouverons:
- assets — Contient le répertoire images qui est copié dans le répertoire assets qui sera créé dans public par le module bundler (Webpack)
- public — Contient le point d'entrée unique de toute l'application: index.php; contient également les fichiers statiques qui doivent se trouver à la racine du serveur HTTP (favicon.ico par exemple) et le répertoire de destination des fichiers statiques qui sera géré entièrement par le module bundler (Webpack)
- src — La très grande majorité de notre code HTML, PHP, JavaScript et CSS vit dans ce répertoire
Quand vous utilisez un framework, vous n'avez normalement aucune raison de vouloir modifier les fichiers qui sont dans public (ou équivalent) et ça n'est de toutes façons pas conseillé parce que mettre à jour le framework risque de modifier ce code.
Nous serons un petit plus flexibles là dessus, le but est également de comprendre et personnaliser tout le processus de gestion des requêtes afin de le rendre le plus rapide possible selon votre cas d'utilisation.
Détaillons maintenant la structure du répertoire src:
- api — Contient les sources PHP qui vont gérer les ressources de type API
- conf — Vous pouvez mettre vos fichiers de config ici. Le projet en contient un par défaut qui est importé par le point d'entrée principal index.php et qui contient juste quelques define histoire de garder les choses simples
- js — Contient le JavaScript pour notre applications. Le bundler s'attend à trouver deux fichiers obligatoires ici:
- vendor.js — C'est l'endroit où vous importez les librairies statiques externes (avec require ou import) par exemple Bootstrap ou encore Moment.js ou React histoire de balancer quelques exemples hétéroclites
- app.js — Le piont d'entrée principal pour les fichiers statiques, vous devriez y grouper votre code JS et y importer les fichiers CSS (voir exemple dans le code)
- lib — Mettez tout ce que vous voulez ici. Vous y trouverez un petit fichier avec un petit peu de code que j'utilise pour générer mes vues sans utiliser de moteur de template (expliqué plus loin)
- styles — Placez vos fichiers CSS ici. Il faudra tout de même les importer d'une manière ou d'une autre dans app.js parce que c'est là que Webpack ira les chercher (voir exemple dans le code)
- views — Les différentes vues routables de notre application. Contient également un important répertoire templates avec tous les partiels (en-tête, pied de page, etc.)
Prérequis
Pour faire tourner le projet nous avons besoin de Node.js (v10+) et PHP Installé localement.
L'interpréteur PHP peut être installé sur toutes les plateformes (oui, y compris Windows). Assurez-vous que l'exécutable php est bien couvert par la variable d'environnement PATH.
Installation des dépendances
Ouvrez votre ligne de commande favorite dans le répertoire du projet et lancez:
npm installVous devriez à présent être en mesure de lancer le serveur de dev avec:
npm run devCe qui devrait rendre l'application accessible à l'adresse http://localhost:8081.
A notez que les fichiers statiques sont également surveillés et les scripts et CSS seront automatiquement reconstruits en cas de modification (vous devez tout de même rafraîchir le navigateur pour que PHP utilise les nouveaux fichiers compilés).
Vous devriez avoir ce genre de résultat (j'avais envie d'avoir un bidule qui tourne moi aussi, j'ai dû voir ça quelque part auparavant):
Déroulement d'une requête
Tout commence par public/index.php de sorte que cette page devrait être la ressource par défaut à charger sur le serveur HTTP si un fichier n'est pas trouvé pour une requête.
Nous fournirons ensuite notre propre page 404 pour indiquer aux utilisateurs que leur requête concerne une ressource inexistant le cas échéant.
Si votre serveur HTTP est Apache 2.2+, vous pouvez utiliser la directive suivant dans votre définition de Virtual Host (au niveau le plus élevé):
FallbackResource /index.phpPour obtenir le même résultat avec Nginx, le plus simple est d'adapter une directive try_files de sorte que index.php soit utilisé comme s'il s'agissait de l'erreur 404.
Le rôle assigné à index.php en lui-même est simple: décider que faire par rapport à l'URL de la requête.
J'ai dû choisir une certaine logique d'URL qui me convient personnellement, vous pouvez adapter index.php pour mettre en place votre propre logique d'URL. Gardez juste en tête de ne pas rendre index.php trop complexe, volumineux et spagettifié parce que c'est notre principal avantage par rapport à utiliser un framework, dois-je le rappeler.
Si index.php ne ressemble plus à rien et vous ne savez plus exactement ce qu'il s'y passe et ce qui est importé, oubliez tout ça et utilisez un framework.
URLs et logique de routage
Par choix de conception nous avons deux logiques séparées pour le routage: une pour les vues, et une pour les ressources API.
Les vues
Pour accéder aux vues dans le cas le plus simples nous cherchons ce type de d'URL:
/view_name.htmlCe qui va provoquer la recherche d'un fichier PHP qui s'appelle view_name.php dans src/views. Si ce fichier n'existe pas, on chargera la vue 404 (qui est prédéfinie dans src/views).
J'ajoute quelques conventions supplémentaires afin de pouvoir fournir des paramètres de requêtes. Il s'agit alors d'utiliser une URL qui ressemblerait à ceci:
/view_name/param1/value1/param2/value2.htmlNotez bien le ".html" qui termine l'URL. Il doit toujours être présent tout à la fin sans quoi index.php n'identifiera pas la requête comme correspondant à une vue.
Cette URL serait toujours traitée comme correspondant à la vue src/views/view_name.php mais ajouterait en plus les paramètres dans une variable globale $app['url_params'].
Par exemple, dans le code de view_name.php, vous pourriez faire ceci:
echo $app['url_params']['param1']; // Affiche 'value1'
echo $app['url_params']['param2']; // Affiche 'value2'Prenons l'exemple concret d'une page qui liste les articles de votre blog. La vue concernée est articles.php et utilise une logique de pagination qui limite le nombre d'articles par page. Vous pourriez utiliser ce type d'URL:
/articles/page/3.htmlEt ensuite consulter les paramètres d'URL dans le code de la vue.
Je reviens brièvement sur la présence obligatoire du ".html" final: selon moi, ça nous donne des URL simples et propres qui en plus indiquent sémantiquement que le serveur va nous envoyer du code de présentation (du HTML, quoi).
Je trouve qu'avoir une information sur la nature de la réponse c'est d'autant plus intéressant que l'on va prévoir d'autres URLs pour accéder à des ressources d'API qui vont nous renvoyer autre chose que du HTML (à savoir du JSON ou XML ou que sais-je).
Tout ça c'est une question de goût mais je sais pas pourquoi on s'obsède pour du "SEMANTIC HTML" avec un minmum de div etc. mais qu'on s'en barre d'avoir des URL qui n'indiquent pas du tout le type de réponse à laquelle on peut s'attendre.
Ressources d'API
Vos endpoints d'API devront également contenir la versoin de l'API en tant que paramètre spécial. Enfin, moi je trouve que c'est bien.
Ce qui nous amène à ce type d'URL:
/api/v1/api_handlerExplications:
- Nous utilisons le /api/ apparaissant obligatoirement en premier comme indicateur qu'il s'agit d'une ressource de type API
- Immédiatement après devrait suivre une chaine de caractères qui représente la version d'API utilisée; la version pourrait être un simple nombre ou quelque chose de plus complexe par ex. v1_2beta
- Vient ensuite le nom du fichier PHP que l'application va tenter de charger depuis le répertoire src/api; nous redirigerons vers une vue 404 si le fichier n'existe pas — C'est la vue 404 qui est dans views qui est utilisée mais vous pourriez en créer une spécifique dans src/api qui renvoie du JSON, XML, ou aucun contenu "body" puisque les en-têtes peuvent être suffisantes pour indiquer une erreur au niveau API
Pour fournir des paramètres nous utiliserons la même logique que pour les vues:
/api/v1/api_handler/param1/value1/param2/value2Ce qui rendra les deux paramètres disponibles au niveau du fichier PHP correspondant comme c'était le cas pour les vues.
Le dépot du projet content un gestionnaire de ressources API d'exemple (example.php) qui contient le code suivant:
<?php
header('Content-type: application/json');
// We have access to URL params in $app['url_params']
// and can wire different responses according to that.
echo json_encode(
[
'hello' => 'world',
'api_version' => $app['api_version'],
'params' => $app['url_params']
]
);Si vous avez le serveur de développement qui tourne, vous pouvez constater par vous-mêmes:
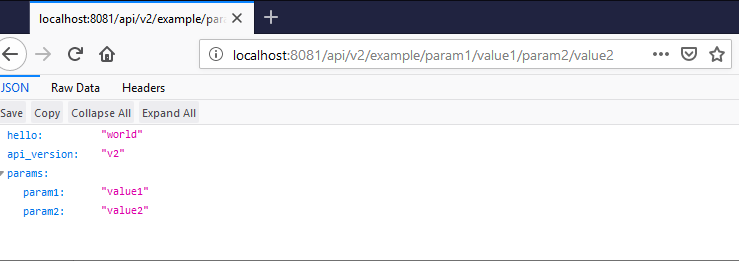
Vous êtes peut-être en train de vous dire "attends il a juste mis content-type sur JSON et vomi le résultat de json_encode et voilà"?
Oui. C'est ça PHP. C'est simple, c'est beau. Davantage comme un concombre de mer qu'une aurore boréale, mais c'est beau quand même.
Vous pouvez structurer vos appels d'API comme vous voulez en observant la version d'API demandée et la présence de certaines clés dans $app['url_params'].
Templating
Le templating mérite une explication parce que là aussi, on suit la philosophie du simple et natif et semi-retour aux sources de quand PHP c'était bien.
Parce qu'en fait, depuis le début, PHP a été créé pour être un "préprocesseur" de HTML et être étroitement couplé à ce même code HTML.
Après des années de code spaghetti infernal et de quantités de bouts de codes coquins planqués au milieu de plusieurs kilobytes de HTML, les gens ont commencé à aborder le concept de separation of concerns que je traduirais par euh... Séparation de... Contexte? OK on va dire spearation of concerns.
L'idée s'inscrit bien dans l'âge d'or du MVC que je décrivais dans l'introduction de cet article (introduction de 10000 pages comme d'hab): Les vues sont censées juste être du code de présentation et rien d'autre.
En pratique, même pour les plus ardents adeptes de separation of concern, ça n'est pas absolument exactement vrai parce qu'il est courant qu'il y ait des logiques conditionnelles dans les templates.
Je vous invite à balancer "separation of concern opinion" sur Google si vous avez besoin de philosophie et de sens à votre vie en ce moment, mais, au cas où vous ne le saviez pas, la manière de voir le concept de separation of concern a changé ces dernières années.
Déjà le concept de MVC en lui-même s'est floutté et plus personne ne râle si votre vue a un peu de code contrôleur et ça, c'était avant que des projets comme React ne foutent la merde en balançant du code HTML (du JSX pour être rigoureux **bruit de prout coulant**) en plein milieu de code JavaScript, avec en plus du JavaScript dans le HTML, et EN PLUS DU CSS DANS LE JAVASCRIPT slmdqkfjmdlskjfmqlksdjfSLFKJkf
Là certains se sont dit "ça y est, y a plus de limite, c'est la fin, Internet Explorer ça va devenir un reskin de Chrome et tout" et puis les choses se sont calmées (sauf pour Internet Explorer qui est véritablement devenu un reskin de Chrome) et l'idée que ces concepts ne devaient pas nécessairement être séparés est redevenue acceptée (voir défendue à coup de pioche cf. nature humaine).
Attention, il convient tout de même d'observer une certain retenue et modestie. Pas question de créer un fichier "contact.php" directement routable avec du HTML entrecoupé de requêtes de base de données et de conditions qui choisissent quelle partie de 30 KB de HTML doit s'afficher. Ceci dit, vous serez le réel arbitre d'à quel point vos vues seront propres ou sales.
J'ai choisi dès lors de ne pas utiliser de moteur de template, et juste d'utiliser PHP. Avec le moins de logique possible, juste écrire des variables, des conditions et des boucles, et ça s'arrêtera là sauf exception.
Je sais que certains vont considérer ça sale, et pour être honnête nous allons manquer de quelques fonctionnalités qui existent des les moteurs de templates comme un mécanisme de cache intégré et un seul appel final à une fonction de rendu qui rend les choses plus propres.
Au final ça n'est pas bien compliqué d'ajouter un moteur de template à ce projet, bourrez-le dans le dossier lib, incluez-le dans vos fichiers vue, et puis c'est parti.
D'expérience il y a deux choses qui se vérifient la plupart du temps quand on utilise un moteur de template:
- On ne réutilise jamais des templates d'un projet à un autre — ou bien la réutilisation demande tellement d'adaptation que simplement avoir les partiels est suffisant (en priant que vous n'ayez pas à passer d'un style HTML/XML à quelque chose comme Jade/Pug);
- Le manque de contrôle sur le mécanisme intégré de caching peut en fait devenir un problème. De plus, la différence de performance est très petite (on ne peut pas conserver des choses en mémoire, vous vous souvenez? Et lire depuis du stockage c'est une opération bloquante pour le CPU!).
Bon du coup, comment on va s'en sortir pour nos vues?
J'ai inclus un moyen de créer des partiels et de leur extraire des variables qui seront directement accessibles.
Il existe un raccourci bien pratique en PHP natif pour inscrire le contenu d'une variable. Imaginons que nous soyons dans la section <head> d'un template, vous pourriez écrire ceci:
<title><?=$title?></title>Ce qui revient secrètement à faire un echo de cette valeur.
Il existe d'autres raccourcis pour les boucles et les conditions, qui se résument à ne pas utiliser les classiques "{}" et plutôt l'écrire comme ceci:
<?php if ($someVariable): ?>
<p><?=$someResultToShow?></p>
<?php endif; ?>Je répète que tout ceci est natif, il ne faut aucune librairie et aucun moteur de template.
Dans src/lib/Templating.php vous trouverez cette courte fonction:
public static function includeTemplate($filename, $vars = array()) {
if (isset($vars)) extract($vars);
include(dirname(__DIR__) . '/views/templates/' . $filename);
}Où j'utilise extract pour rendre les clés et valeurs du tableau associatif $vars disponibles au sein du partiel. Ensuite, j'inclus le dit partiel.
Lier le contenu statique compilé
Je rappelle que l'on utilise Webpack pour rassembler tout notre JavaScript et CSS en un nombre limité de fichiers (trois: le fichier CSS, le fichier de code "vendor" JS, et le fichier JS principal) qui pourront ensuite être mis en cache pour une durée indéterminée par le navigateur des clients puisque toute modification de ces fichiers provoquera un changement de leur nom.
Par conséquent il est nécessaire de fournir un moyen pour PHP de connaître le nom des fichiers statiques à importer, puisque ce nom peut changer (je me répète mais au point où on en est...).
Webpack est configuré pour sortir un fichier "manifest" qui peut ensuite être lu par les scripts PHP pour trouver le nom exact des fichiers. Une fonction appelée getAssets (src/lib/Templating.php) remplit précisément ce rôle et renvoie un objet contenant les noms des modules statiques en tant que clés de cet objet.
Si vous jetez un oeil à la vue exemple src/views/index.php, vous verrez que cet objet est passé aux deux partiels header.php et footer.php, qui vont respectivement utiliser cette variable comme suit:
<link rel="stylesheet" href="<?=$assets->{MAIN_CSS_BUNDLE}?>" /><script src="<?=$assets->{VENDOR_JS_BUNDLE}?>"></script>
<script src="<?=$assets->{MAIN_JS_BUNDLE}?>"></script>Je procède de cette manière parce que je veux avoir mon import CSS dans <head> et mes imports JS à la fin de <body>.
Les constantes MAIN_JS_BUNDLE et MAIN_CSS_BUNDLE sont définies dans src/conf/config.php afin de correspondre aux noms des modules dans manifest.json et comme définis dans la config de Webpack. Au moment où j'ai décidé de faire ça je trouvais ça cool. Maintenant on est obligés de le garder. C'est un peu comme mon chat.
Comment inclure du contenu statique à compiler
Webpack est configuré pour utiliser deux points d'entrée: src/js/app.js et src/js/vendor.js.
Toutes vos feuilles de style devraient être importées dans app.js. Si vous regardez le contenu du fichier tout frais du dépot vous verrez la ligne:
import '../styles/styles.scss';Si vous êtes perspicaces, vous aurez remarqué que nous avons du support SCSS actif immédiatement. C'est typiquement quelque chose qui vous prendrait un temps non-négligeable à essayer de coller à votre Symfony ou Laravel de la manière qu'il recommandent. Ou de n'importe quelle manière d'ailleurs.
Bien entendu, vous n'êtes pas obligés d'utiliser SCSS, vous pouvez simplement importer des fichiers .css normaux et tout ira bien, je vous le promet.
Si vous êtes particulièrement chauds en terme de performances parce que vous suivez des développeurs Chrome sur Twitter, sachez que vous pouvez facilement ajouter des points d'entrées supplémentaires à la config. de Webpack afin de créer de nouveaux bundles.
Ces nouveaux bundles peuvent alors être chargés sélectivement sur les vues qui les utilisent, et sur ces vues là uniquement. Par exemple, vous pouvez regrouper le CSS et JavaScript utilisé pour la section blog de votre site dans son propre bundle en ajoutant l'entrée "blog" suivante à l'objet "entry" dans webpack.config.js:
const config = {
entry: {
app: './src/js/app.js',
vendor: './src/js/vendor.js',
blog: './src/js/blog.js'
},
// Rest of the Webpack Config
};Webpack créera un nouveau bundle basé sur "blog.js" qui apparaîtra également dans le manifest (à la clé "blog"). Vous devrez alors manuellement l'importer dans les vues qui sont concernées.
Cette manipulation est parfois appelée "code splitting" si vous voulez le vrai terme des grands garçons et grands filles. Ajouter davantage de code splitting peut rendre votre application encore plus rapide en limitant la quantité de JavaScript et CSS qui est chargée sur les premières pages visitées par vos utilisateurs.
Dois-je rappeler que Google se base également sur les performances de votre site pour son classement dans les résultats de recherche?
Performances
Quelqu'un trouvera toujours quelque chose à redire sur ces tests qui sont juste une vague indication; mais une vague indication qui est beaucoup plus catégorique que je pensais.
Je pensais bien que mon bidule serait plus rapide que Symfony ou Laravel mais je pensais pas que ce serait à ce point là.
J'essayerai de donner deux ou trois pistes qui pourraient peut-être réduire le fossé.
Commençons par expliquer comment j'ai procédé aux tests.
Je choisis de tester contre Symfony uniquement. Parce que j'ai pas que ça à faire et que c'est de loin le framework le plus populaire en francophonie. Par ailleurs, j'imagine qu'ils se sont bien pompés l'un l'autre et sont similaires en terme de performance par vertu des glorieuses lois du marché.
Je crée donc un projet Symfony avec composer:
composer create-project symfony/website-skeleton bench-symfonyTant pour Symfony que pour mon projet, tout se passe dans le point d'entrée principal index.php, je devrais donc pouvoir calculer le temps que PHP a pris pour générer la page depuis ce fichier.
Je commence par désactiver le mode dev de Symfony, sans quoi index.php est appelé deux fois et surtout, j'imagine qu'il y a du code en plus qui est chargé.
J'ai créé une application à partir de mon projet également, avec la même structure de réponse pour la page d'accueil: une page avec deux partiels header et footer et qui dit juste Hello World.
A savoir que pour Symfony j'ai utilisé le moteur de template Twig, parce que c'est ce que vous êtes censés faire.
Toujours sur le projet Symfony, j'ai ensuite modifié index.php pour conserver un timestamp microtime tout au début du fichier et calculer la différence en millisecondes tout à la fin.
Je vous colle le code ici juste pour illustration:
<?php
$start = microtime(true);
use App\Kernel;
use Symfony\Component\Debug\Debug;
use Symfony\Component\HttpFoundation\Request;
// ... MORE SYMFONY STUFF
$kernel = new Kernel($_SERVER['APP_ENV'], (bool) $_SERVER['APP_DEBUG']);
$request = Request::createFromGlobals();
$response = $kernel->handle($request);
$response->send();
$kernel->terminate($request, $response);
echo 'ELAPSED ' . (microtime(true) - $start) * 1000;Le résultat apparaît alors en bas de la page quand je l'appelle. C'est moche mais ça fonctionne.
J'ai répeté cette opération pour mon projet, à savoir que j'ai copié-collé la première et la dernière instruction (le $start = microtime(true); et le echo qui est tout à la fin).
Comme environnement de test j'ai choisi Docker. Une fois les applications construites (npm run build pour mon projet et être bien certains d'avoir terminé composer install pour Symfony) j'utilise ce Dockerfile bien moche:
FROM php:7.3-apache-stretch
COPY . /var/www
RUN rm -rf /var/www/html && ln -s /var/www/public /var/www/html
WORKDIR /var/www/html
EXPOSE 80
CMD ["apache2-foreground"]J'avais intialement créé des Dockerfiles qui désactivent opcache, puisque je me disais qu'avec opcache activé les résultats allaient sans doute être tout le temps les mêmes et donc extrêmement rapides. En fait... Je ne vois aucune différence avec ou sans opcache. Honnêtement je pense que l'explication c'est juste que je capte rien à opcache, mais qui sait?
L'important c'est que le fossé entre mon projet et Symfony existe même avec opcache actif (avec ses options par défaut, évidemment). Oui, je sais que j'arrête pas de vous spoil les résultats mais je suis tout excité, moi.
Reste plus qu'à faire peter un tableur et récolter une vingtaine d'échantillons pour chaque application.
J'obtiens ces résultats en millisecondes pour la moyenne des deux applications:
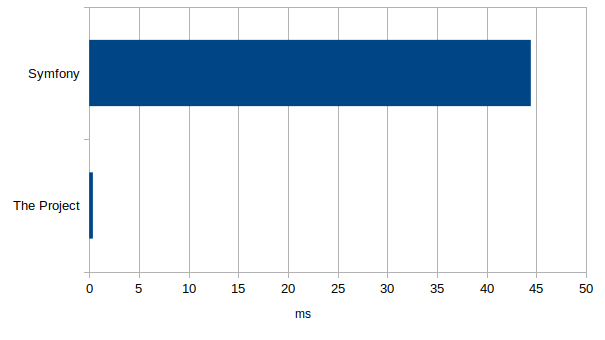
En gros, mon projet est 118 fois plus rapide d'après PHP.
Histoire d'être certain que je n'hallucine pas, j'ai vite écrit un script moche en JS qui compte combien de temps il faut pour avoir une réponse du serveur, ce qui est un peu foireux par définition parce que JavaScript est loin d'être en temps réel et est asynchrone par nature et en plus on a le délai dû à la requête réseau elle-même qui s'ajoute.
Résultat: le fossé est beaucoup moins profond, cette fois-ci j'ai 15ms en moyenne pour mon projet et 50ms pour Symfony.
En fait, après un test sur juste un Nginx vide, il semblerait que 15ms ça soit le minimum absolu pour Node.JS.
J'ai réessayé avec curl histoire d'avoir quelque chose de peut-être plus réaliste et généreux, et là j'obtiens 5ms pour mon projet et 63ms pour Symfony. Et faut que j'arrête d'appeler ça mon projet ça me rappelle une campagne présidentielle cette histoire.
Dans ce cas là Symfony n'est que 12.6 fois moins bien. Vous pouvez utiliser ce chiffre-là si vous préférez, moi je m'en fous j'ai gagné.
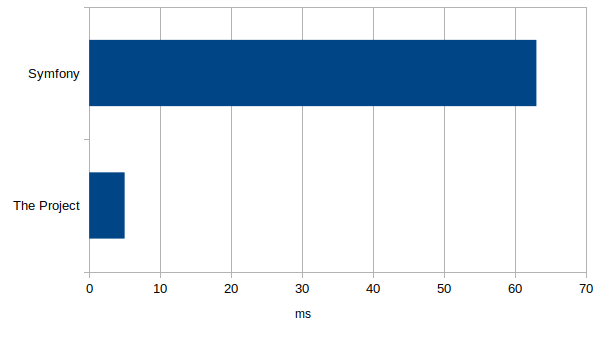
Comment c'est possible que la différence soit si élevée? D'autant plus que j'ai laissé l'histoire du manifest pour les fichiers générés par Webpack pour mon projet, c'est-à-dire qu'il y a une lecture de fichier disque à chaque requête en plus d'une interprétation du JSON dans mon cas. Honnêtement je pensais que cette opération allait peut-être égaliser les chances. En fait pas du tout.
Je suppose que Symfony doit charger beaucoup plus de fichiers différents pour assembler son Kernel et gérer la requête.
Est-ce qu'avec un stockage plus rapide (en temps de réponse en tous cas), ce serait mieux? Le stockage de mon ordinateur portable est un SSD M.2. J'évoquais plus haut qu'il était possible d'utiliser un ramdisk. Il faudrait vérifier si ça aide.
Est-ce que c'est simplement tout le moteur de template Twig qui ralentit l'affaire à ce point-là? Il faudrait tout profiler pour voir mais j'ai pas que ça à faire. Bon OK... Je le ferai peut-être un jour :D
Notons également qu'il y a moyen d'optimiser Symfony pour la production. Ils ont de la doc là dessus. C'est un peu galère, je ne suis pas fan des technologies qui demandent deux ans d'étude pour en tirer le maximum.
Je pense que ce test a plutôt prouvé ce que j'essayais de prouver sans penser que j'allais arriver à le prouver.
Trucs un peu foireux et possibilités d'amélioration
Il y a des tas d'améliorations possibles pour le projet de base que cet article décrit.
J'ai déjà passé 1000 ans à écrire cet article beaucoup trop long que je dois encore relire et modifier une centaine de fois alors comprenez que là, je vais faire une petite pause.
Voici tout de même quelques éléments de discussion.
Y a pas de cache
Si vous êtes arrivés jusqu'ici j'imagine que vous avez lu ma diatribe sur le modèle d'exécution de PHP et vous êtes au courant qu'il a quelques problèmes dès qu'il s'agit de conserver des données entre les requêtes. Et ces quelques petits problèmes c'est qu'il n'a pas du tout de moyen de le faire du tout.
Par conséquent, mettre toutes sortes de trucs en cache permet d'éviter de devoir reconstruire ces structures à chaque requête d'un client.
Habituellement, des fichiers sont utilisés pour stocker ce cache, et certaines librairies (comme les moteurs de template) embarquent leur propre système basé sur des fichiers.
Quoi qu'il en soit, il existe toujours une condition limite avec les applications PHP (et les applications web en général) à partir de laquelle les performances de l'application sont entièrement dépendantes des performances des mécanismes de caching mis en place.
On a la chance de vivre à une époque où toutes sortes de chouettes projets peuvent servir pour construire cd "cache", même s'il ne s'agit pas réellement d'un cache (je pense à Elasticsearch).
Tout ça pour dire que je n'ai rien implémenté en terme de caching de base. Pourtant il pourrait exister un mécanisme qui conserve une partie des blocs utilisés dans les templates (par exemple les blocs <script> créés à partir du manifest).
Par ailleurs, c'est pas trop mon genre de donner mon opinion mais je dois dire que pour les petits applications, je pense que trop de caching crée plus de délai que de gain.
Pas de transpilage
Je sais pas si ça se dit transpilage.
Le code JavaScript moderne (la partie développement pas la partie construite que vous pouvez télécharger) est générallement écrit en ES6/ES2015 que les navigateurs comme Internet Explorer 11 ne sont pas capables d'utiliser.
Plus grave, le Google Bot actuel ne supporte pas le code ES6 non plus. Je parle de tout ça dans un autre article: Faut Il Vraiment Supporter IE11?
Pour obtenir la compatibilité requise le JavaScript utilisé en production est presque toujours passé dans un "transpileur", transpilonner, compilateur, euh... Un truc qui s'appelle Babel.
Pour l'ajouter dans le projet il s'agit de modifier la config de Webpack et lui ajouter un loader pour les fichiers .js, ainsi qu'ajouter une config pour Babel (le preset "env" suffit).
Par choix personnel, je préfère ne pas avoir Babel présent de base. C'est un drôle de choix personnel et je m'en veux un peu de vous emballer dedans.
Il y a beaucoup d'articles sur comment ajouter le support Babel à Webpack, j'ajouterai peut-être des explications dans le fichier README.md du projet si j'en ai l'occasion.
Dites-moi dans les commentaires si ça vous intéresse et je trouverai le temps de le faire parce que je vous aime bien.
Minification CSS et autoprefixer
Nous ne faisons pas du tout de minification CSS et l'autoprefixer n'est actif que sur les fichiers SCSS.
Il s'agit juste de trouver la force de se plonger dans la config Webpack. Je suis pas prêt là.
Ajouter un Dockerfile
Tester l'application avec le serveur de dev de PHP c'est facile mais la performance générale peut s'avérer très moyenne et puis il faut aussi s'assurer d'avoir toutes les extensions PHP nécessaires localement installées et ce processus n'est pas le même selon votre plateforme. Certaines extensions se comportent différemment selon la plateforme, ce qui n'aide pas non plus.
Ce serait mieux de décrire l'environnement dans un Dockerfile et l'utiliser pour les tests, le développement, et la production.
Y a pas de tests
Les frameworks PHP sortent tous du four avec un système de test intégré.
Les tests, c'est important (je vous jure, c'est pas une blague) et ça peut être réalisé de différentes manières.
J'ai tendance à préférer mettre en place quelque chose en JavaScript où on a accès à des tonnes de projets intéressants tels que Puppeteer et Jest mais au final ce serait sans doute intéressant d'avoir quelque chose de basé sur PHPUnit également, ou des tests en PHP natif histoire d'encore mieux coller à la philosophie du projet.
Pas de joli "dev mode"
Les frameworks PHP fournissent des outils de profilage et déboguage qui s'activent automatiquement quand vous visitez votre application en "mode dev".
Personnellement je n'utilise jamais ces fonctionnalités. Si j'ai besoin de profiling je l'ajoute directement dans le code sur une branche de test du dépot Git.
Je peux comprendre pourquoi certaines personnes s'y seraient attachées, ceci dit.
Conclusion
J'espère avoir illustré que vous n'avez pas nécessairement besoin d'un framework PHP pour faire quelque chose de moderne, rapide (118 fois plus rapide lel) et avec une compilation des fichiers statiques présente de base et une structure claire bien que flexible pour ce qui est du code des vues et du modèle.
Reprenez le contrôle de votre PHP, comprenez-le, soyez efficaces.
Commentaires
Il faut JavaScript activé pour écrire des commentaires ici