

Depuis que j'utilise une single page web app comme blog, poster un lien vers un de mes article sur un réseau social ne produit plus une carte avec une image, une courte description, ce genre de choses.
La plupart des sites avec du contenu de type articles, vidéos, etc. Utilisent des tags particuliers pour apparaître de manière plus propres sur les réseaux sociaux.
Que je sache, les premiers à avoir affiché un standard pour ce que est de leur réseau social, c'est Facebook, avec un projet qui s'appelle Open Graph.
Le problème c'est que ça utilise des tags <meta> dans la balise <head>, et les modifier avec du Javascript n'a aucun effet parce que les robots des réseaux sociaux ne l'interprètent pas.
Skoi une SINGLE PAGE WEB APP
Je vais plutôt commencer par là.
Une app mono-page, app page unique, app simple page, euh... Je n'ai absolument aucune idée de comment ça se traduit.
Il s'agit d'un site web avec... Une seule page (index.html en général). Cette page gère tout ce dont le site est capable et est dès lors en mesure de modifier le contenu affiché et éventuellement de faire des requêtes de type AJAX.
Comment cette page HTML fait tout ça? Ben... Avec du Javascript. Vous savez pas encore qu'on peut tout faire avec du Javascript? Des programmes compilés qui prennent 200 MB de RAM, des applis serveur, des applis serveur et client à la fois (???) et d'autres trucs du futur avec une super gestion de dépendance qui fait que si on veut juste un outil de packaging web il faut 80 MB de code à télécharger sur 3000 sous-dépendances différentes.
[Trou de contexte] - Petit carousel de dépendances pour un projet web qui utilise juste Webpack, aucun framework JS etc. (NONON CA FAIT PAS PEUR):
En fait les single page web apps (SPA) sont une mauvaise idée en règle générale.
leur seul avantage réside en leur réactivité, qui est maximale puisque les seules requètes réalisées le sont par Javascript de manière transparente et récupèrent des quantités très limitées de données (du JSON dans la plupart des cas).
Le prix à payer c'est que sans Javascript, ben... Il se passe rien et on ne voit rien.
Historiquement les robots des moteurs de recherche n'exécutaient pas le Javascript.
Ce n'est plus le cas aujourd'hui pour les moteurs de recherche qui importent, mais les robots qui cherchent comment afficher vos ressources sur les réseaux sociaux, eux, n'exécutent toujours pas le Javascript.
Même si on vivait à une hypothétique époque où tous les robots crawler exécutent le Javascript, une app simple page n'a en théorie qu'un seul jeu immuable de tags dans <head>.
Alors oui, on peut changer document.title en JS, on peut créer et modifier des tags dans <head> mais c'est pas trop fait pour.
Je pense ne pas prendre beaucoup de risque en supposant que tous les sites majeurs sur Internet utilisent un rendu serveur, avec quelques bidules AJAX, mais ils n'utilisent pas une absolue mono-page HTML pour TOUT. Personne ne fait ça.
Sauf... Si vous utilisez une technologie comme Angular, ou Polymer, ou React, tels quels (parce qu'il est bien entendu tout à fait possible d'utiliser ces technologies avec une partie en rendu serveur).
Et puis moi je le fais aussi. Oui je viens de vous dire que c'était une mauvaise idée.
J'aime bien l'idée d'avoir la "partie client" qui tienne toute seule et ne dépende d'aucune technologie serveur.
Ceci m'a permis par exemple de passer d'un backend Play Framework à un Spring Boot totalement différent sans à avoir à faire quelconque adaptation pour ma partie client, alors que j'aurais normalement dû adapter des templates et tripoter mes scripts de compilation de la partie client (avec Webpack dans mon cas) pour que ça crée la sortie dont j'ai besoin.
Avec ma monopage indépendante, je ne dois rien faire pour changer de backend.
C'est un drôle d'avantage... Et c'est pourquoi je maintiens qu'une app strictement mono-page est une mauvaise idée.
A moins qu'il s'agisse d'une application web qui ne fait qu'une seule chose, comme par exemple euh... Une calculatrice en ligne (VEZDE skoi cet exemple à la con??) ou un jeu.
Références
Cet article est ma propre version d'informations glânées par-ci par-là.
Mention honorable à quelques articles qui sont l'inspiration principale et dont vous aurez besoin si, par exemple, vous travaillez avec Apache et pas Nginx.
- Ma source principale: www.michaelbromley.co.uk/blog/enable-rich-social-sharing-in-your-angularjs-app
- Un exemple bien court et concis (pas comme cet article, quoi) avec du PHP: rck.ms/angular-handlebars-open-graph-facebook-share
Open Graph
Open Graph n'est pas la seule méthode pour partager du contenu "social". Mais comme ils étaient là avant, c'est supporté par Twitter par exemple, qui pourtant a sa propre version de tags de contenu social.
La priorité est donc de gérer Open Graph. Qui n'est que moyennement Open et que-je-comprends-pas pourquoi il y a "Graph" dedans. Mais c'est pas grave.
Pour ajouter Open Graph à une page (article, vidéo, etc.) il faut ajouter le namespace au tag HTML:
<html prefix="og: http://ogp.me/ns#">Comme mon contenu, ce sont des articles, j'avais l'intention d'ajouter ces informations:
<meta property="og:title" content="Titre de l'article" />
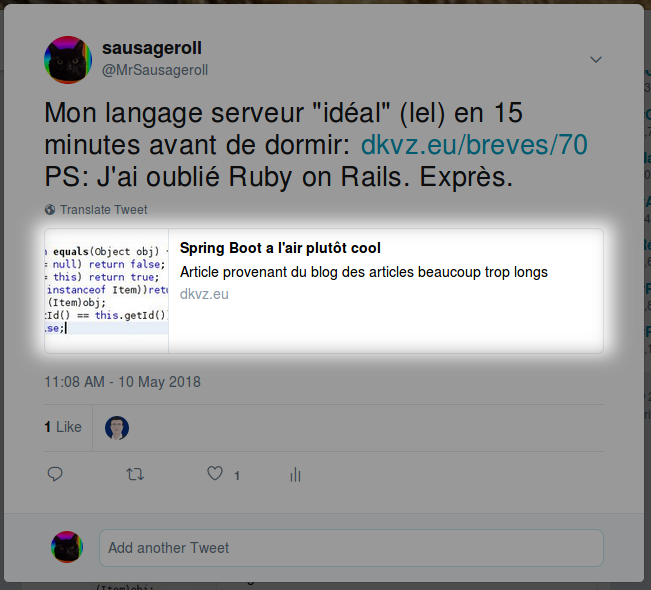
<meta property="og:description" content="Article provenant du blog des articles beaucoup trop longs" />
<meta property="og:url" content="URL de l'article" />
<meta property="og:image" content="Thumbnail Image URL" />
<meta property="og:type" content="article" />A noter que la description est normalement un extrait de votre article, d'une longueur max d'environ 200 caractères. Non applicable pour moi parce que j'ai du HTML dans mes résumés d'article.
Il existe des descripteurs pour ajouter la taille de l'image, ce que Facebook semble apprécier. Mes images sont de tailles variable donc je n'ajoute pas la taille.
Pas de panique, beaucoup de sites, dont Medium.com, n'ajoutent pas la taille de l'image non plus.
Tant qu'à faire j'ajoute aussi ces éléments parce que je les ai vus sur d'autres sites, mais je pense que ça ne sert à rien.
<meta property="article:author" content="Author" />
<link rel="author" href="Author" />
<meta property="author" content="Author" />
<meta property="article:published_time" content="Publication Date ISO format" />
<meta property="og:site_name" content="dkvz.eu" />OK mais on ajoute ça où?
C'est là que nous allons recourir à un horrible hack.
L'idée est de détecter l'user-agent des robots de réseau sociaux et leur renvoyer une page générée par le serveur plutôt que par du Javascript.
Bon, du coup c'est plus compliqué si vous n'avez pas du tout de "partie serveur". Genre si vous avez juste Github Pages ou un truc sur Netlify.
Si vous avez une "partie serveur", en PHP, Python, Java, etc. Il va falloir ajouter un chemin pour générer une page pour vos articles (ou vidéos, podcasts, etc.) avec tous les meta tags, et éventuellement tout le contenu aussi (je pense que c'est mieux).
La génération côté serveur
Cette partie là dépend de votre technologie serveur.
J'utilise Spring Boot avec le moteur de template Thymeleaf.
J'ai simplement ajouté un endpoint à mon service Rest: render-article, auquel on concatène une URL d'article ou un identifiant.
J'utilise ce template.
Exemple pour cet article: api.dkvz.eu/render-article/single_page_app_open_graph
Avec absolument aucune info de style et une disposition bien moche.
La "redirection"
Il ne s'agit pas vraiment d'une redirection à proprement parler, qui demande une nouvelle requête, il s'agit plutôt de passer la requête modifiée par proxy à la partie serveur de manière transparente.
Voici normalement comment la configuration de mon site est faite:
- Vérifier si la ressource demandée existe ;
- Si oui, servir la ressource.
- Si non, servir index.html.
Et c'est tout. Vous pouvez vérifier en tapant https://dkvz.eu/image_qui_existe_pas.jpg
C'est la page index.html qui s'affiche (le site, quoi, puisque le site c'est une seule page) avec un message qui indique que le Javascript n'a pas récupéré de contenu en plus, donc la page vous annonce que la ressource demandée n'existe pas et que vous avez été redirigé vers la page d'accueil.
En fait c'est un gros mensonge, il n'y a pas eu de redirection, le serveur vous a juste servi index.html tel quel à la place de ce vous demandiez.
La page index.html réalise des requêtes AJAX vers api.dkvz.eu, qui est un autre site avec une autre configuration où là, on passe les requêtes à Java par reverse-proxy.
Il va falloir adapter le site principal pour qu'il passe aussi certaines requêtes à Java.
Dans tous les cas il va falloir détecter les User-Agent des robots de réseaux sociaux, sans chopper le robot d'indexation de Google (et apparentés Bing etc.) qui lui, exécute le Javascript. Le but est d'uniquement interceter les requêtes de robots de réseaux sociaux.
Difficile d'avoir quelque chose d'absolument exhaustif, il faudrait probablement que je m'attarde aux nouveaux réseaux sociaux comme minds.com.
Dans l'état actuel des choses, j'utilise ce bloc "if" sur Nginx:
if ($http_user_agent ~ baiduspider|facebookexternalhit|Twitterbot|twitterbot|rogerbot|linkedinbot|embedly|quora\ link\ preview|showyoubot|outbrain|Pinterest|pinterest|slackbot|vkShare|W3C_Validator|Facebot|facebot|Google.*snippet) {
}C'est un peu sale, mais ça fait le taf.
Ensuite, dans mon bloc "server", j'ai ces blocs "location":
location /articles {
if ($http_user_agent ~ baiduspider|facebookexternalhit|Twitterbot|twitterbot|rogerbot|linkedinbot|embedly|quora\ link\ preview|showyoubot|outbrain|Pinterest|pinterest|slackbot|vkShare|W3C_Validator|Facebot|facebot|Google.*snippet) {
rewrite /articles/(\w+)$ /render-article/$1 last;
}
try_files $uri /index.html =404;
}
location /breves {
if ($http_user_agent ~ baiduspider|facebookexternalhit|Twitterbot|twitterbot|rogerbot|linkedinbot|embedly|quora\ link\ preview|showyoubot|outbrain|Pinterest|pinterest|slackbot|vkShare|W3C_Validator|Facebot|facebot|Google.*snippet) {
rewrite /breves/(\w+)$ /render-article/$1 last;
}
try_files $uri /index.html =404;
}
location /render-article {
# This matches the rewrites to the pages rendered by the API.
proxy_pass http://localhost:9001;
}
location / {
try_files $uri $uri/ /index.html =404;
}Bon je pense pas que ça soit optimal parce que je répète les blocs if deux fois (sans compter les trucs inutiles dans cette config genre le =404 qui n'est jamais utilisé et l'absence d'un bloc pour mon contenu statique mais on est pas là pour me juger n'est-ce-pas (ALORS PQ TU FEE UN BLOG??)). En effet, j'ai besoin de rediriger les robots uniquement s'ils demandent les ressources qui sont sur les chemins /articles/ et /breves/.
Ce qui se passe c'est que pour ces chemins, si l'user-agent est repéré dans mon affreuse liste probablement-non-exhaustive, je modifie l'URL demandée de manière interne (c'est un "remapping" en pratique) en /render-article/ suivi de l'identifiant de l'article ou de la brève.
Nginx passe alors dans le bloc location pour /render-article qui passe la requête à un autre serveur sur le port 9001 qui est en fait mon application Spring Boot.
Et ça fonctionne.
Comment tester si ça fonctionne?
Outre le test de simplement poster une URL sur Facebook ou Twitter, ces deux sites proposent des outils de debug pour les meta données sociales.
Dans les articles que je mentionne comme références, plusieurs outils de test sont cités. Moi je vous en présente deux pour Twitter et Facebook.
Trouvez l'outil ici: Débuogueur Facebook
Il semblerait que cet outil conserve un genre de cache infernal, donc ne vous inquiétez pas si ça ne fonctionne pas après modification, même en demandant un nouveau scan.
Le mieux c'est d'essayer une nouvelle URL.
Je rappelle que je n'ai pas du tout implémenté les meta données spécifiques à Twitter puisqu'Open Graph fonctionne aussi.
Ceci dit, avec Twitter, vous pouvez ajouter des informations supplémentaires (Medium.com ajoute le temps de lecture estimé). Je vous laisse faire vos recherches vous-mêmes si ça vous intéresse.
Commentaires
Il faut JavaScript activé pour écrire des commentaires ici