

Le Gédépé-air
Aaah... Le GDPR. On en a tous entendu parler, personne ne sait exactement ce qu'il faut faire avec précision, les services légaux se pressent à rédiger divers accords et autres contrats afin de ne pas oublier d'installer un antivirus sur le logiciel qui détecte le niveau restant de papier hygiénique sur la toilette connectée du rez-de-chaussée.
Je pense qu'on a un peu de temps avant qu'il n'y ait une réelle conséquence légale de cette loi en terme de poursuites et dédommagements (suite à une fuite d'information par exemple).
En fait, l'idée du GDPR était surtout (selon moi, mais je pense selon tout le monde aussi) d'imposer des règles et un genre de contrôle sur les géants de l'information et du BIG DATA comme Facebook et autres Google.
Si le boucher Franck Defruscheleer a laissé trainer un tableau Excel avec trois commandes qui lui ont été passées par email sur son comptoir et a dû rapidement rejoindre l'arrière-salle pour répondre à une urgence d'effondrement d'une pile de côtes à l'os alors que l'heure d'affluence suivait son cours et que plusieurs clients auraient pu avoir accès aux données, il y a des chances qu'il ne doive pas payer 130€ à chaque victime de cette terrible fuite de données personnelles.
Enfin... Je pense. A nouveau, il faudra voir ce qui va ressortir vraiment de cette loi (à mon avis pas grand chose LUL).
Quand on voit comment tout un chacun décide d'interprêter les consentements à sa manière, avec parfois un petit popup en bas de page:
Si tu cliques "d'accord", tu accepte que tes données personnelles soient désormais notre propriété avec tout ton consentement maximum et pour toujours. Allez, bonne visite et grosses bises au chat :)
Je ne suis pas certain que ça soit légal. Mais qui va poursuivre ces gens?
L'europe a d'autres trucs à faire. Notamment gérer ces pays qui décident de faire des "referendum" et puis se rendent compte que les gens sont hyper influençables, et que si on leur dit qu'une armée de Polonais arrive tous les ans pour voler leur travail et que sortir de l'Europe sera la meilleure solution je-vous-jure, ils y croient.
Non mais sérieusement, ça ne fonctionne pas les referendum. Peut-être éventuellement en Suisse parce que tout le monde est riche, beau et intelligent là-bas, mais pas ailleurs.
A côté de ça, le fait que Facebook possède une centaine de photos de votre PAQUET a finalement peu d'intérêt.
Ils vont faire quoi, l'imprimer sur des mugs?
La pseudonymisation
Le mieux c'est de ne conserver absolument aucune donnée personnelle. Oui je passe de votre paquet à ça. A savoir que les adresses IP qui sont dans tous les logs de serveur sont considérées comme des données personnelles.
Ceci signifie que normalement, il ne faut garder les logs que pendant une durée minimale, alors qu'auparavant on nous avait demander de les conserver une assez longue durée???
Vous savez, pour capturer les pédophiles et tout ça.
Mais je m'égare.
Il y a deux solutions simples pour tout de même analyser des comportements sur des données qui pourraient identifier quelqu'un.
La première consiste à tout anonymiser. Du coup on ne peut plus du tout identifier qui que ce soit. Et donc c'est pas vraiment une solution. (?????????)
La seconde consiste à pseudonymiser. Au lieu de prendre un visiteur unique et l'identifier par son adresse IP, on remplaçe ça par un pseudonyme. Comme Franck, Philippe, ou Jean-Antoine de Suzac.
Vous avez aussi des mécanismes de génération de noms de fichier, de conteneur (je pense à Docker) et de tous ce genre de choses qui sont également des pseudonymes.
Par ex. un service vidéo qui renomme automatiquement ce que vous venez d'uploader en GentilCapybaraObèse.mp4.
Ma solution simple
Je pense immédiatement aux algorithmes de hachage. Une fonction de hachage est à sens unique en celà qu'il est impossible de trouver la donnée originelle en fonction du haché.
Par contre, si on passe les mêmes données dans la fonction de hachage, on obtient toujours exactement la même réponse.
A contrario, modifier ne serait-ce qu'un petit détail dans la donnée source est censé résulter en un hash totalement différent (et pas un petit peu différent).
Par exemple, le sha1 de la suite de caractères "jambon fumé" est:
F8B4495C58A9DCDC89CAEBE174502A3EFC4D7A66
Et "jambon sec":
BA6F464703326CB9FBA354D9873A81B7781893D4
Vous constatez que c'est totalement différent alors qu'il s'agit de jambon dans les deux cas.
Qu'est-ce que j'explique bien.

Cela étant, j'aimerais bien pouvoir enregistrer autre chose qu'une série de chiffres hexadécimaux pour pouvoir identifier un visiteur, une plaque d'immatriculation, ou une combinaison de différentes choses considérées comme données personnelles (par ex.: Personne A: "chauve, marcel orange, bottes en cuir").
Je pourrais de cette manière compter le nombres de chauves en marcel orange et bottes de cuir, sans savoir qu'il s'agit en de chauves en marcel orange et bottes de cuir.
Vous suivez?
Utiliser un dictionnaire
Mon plan est de faire correspondre n'importe quelle chaine de caractère à un mot d'un dictionnaire (à fournir).
Ce qui signifie qu'un nombre infini de possibilités de données doit se résoudre à un ensemble fini de possibilités. Ce qui correspond à ce que fait une fonction de hachage.
Vous pouvez passer toute la bible ou une blague Carambar dans une fonction de hachage, vous aurez exactement le même nombre de bits en résultat.
Au départ je voulais partir sur des prénoms, mais il n'y a vraiment pas assez de prénoms...
Alors j'ai trouvé un dictionnaire de mots anglais en TXT (je ne sais même plus ou je l'ai trouvé, j'ai honte de ne pas pouvoir saluer le moine qui a recopié tout ça :/). Taille totale: 466462 mots.
Pour la fonction de hachage, honnêtement n'importe quoi convient, y compris le bon vieux md5. Je ne sais pas trop pourquoi je suis parti sur sha1 à la place.
Sha-1 produit toujours un résultat de 160 bits de long (ça en fait des bits).
Cela représente 2
Pour limiter, j'ai décidé de ne garder que les 64 premiers bits du hash. Pourquoi les premiers? AUCUNE RAISON. Pourquoi 64? C'est la taille d'un "long integer" en Java, ça peut toujours servir si je décide d'agrandir mon dictionnaire plus tard puisque 64 bits représentent 9,223,372,036,854,775,807 de possibilités (oui, ces nombres ont des articles Wikipedia).
C'est encore un tout pitit pitit peu trop par rapport à mon dictionnaire mais on fera avec.
Il s'agit maintenant de réfléchir à un PLAN...
OKAY donc combien de fois je peux faire rentrer tout mon dictionnaire dans ces 64 bits? Je me suis dit que c'était cool de faire ce calcul parce que comme ça je peux faire correspondre toute une série de valeurs de hash sha-1 à un seul mot du dictionnaire.
C'est à dire que je partitionne mon dictionnaire.
NB: Il se peut que j'aie choisi une manière non-optimale d'arriver à mon résultat mais mon cerveau ne pouvait pas en faire plus sans s'élever vers un autre plan d'existence cosmique vers un nouvel âge réminiscent.
En Java j'en suis arrivé à ça:
this.increment = Long.MAX_VALUE / Math.ceil(this.count / 2.0d);Où this.count est le nombre d'entrées du dictionnaire, et Long.MAX_VALUE est en fait la moitié de 64
Attends... Pourquoi la moitié?? Parce qu'un Long possède un bit de signe, il va de -MAX_VALUE à MAX_VALUE. Donc je me suis dit que c'était bien de diviser l'affaire en deux (???????).
Je vous ai fait un dessin pour mieux comprendre:
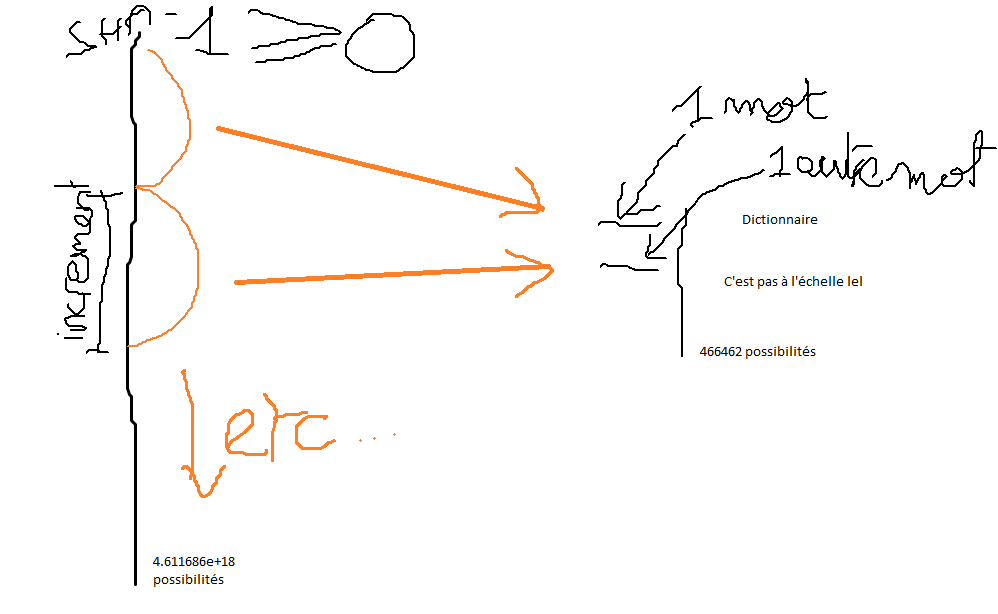
En découpant ce procédé en deux, pour les valeurs de sha-1 plus grande ou égales à 0, et celles qui sont plus petites que 0.
En résumé, chaque groupe de valeurs de sha-1 qui correspond à un incrément correspond à un seul mot.
Ce qui m'a amené à écrire cette magnifique classe Java (rires).
Je ré-ouvre chaque fois un fichier texte, ce qui est moyennement optimal. Mais je n'avais pas envie de stocker plus de 400 000 mots en mémoire, surtout que les String Java prennent 16 bits par caractères.
Puis de toutes manières quand j'utilise ce truc je le fais de manière asynchrone.
Exemple de service
Mes articles ont toujours un double-objectif obscur et celui-ci ne déroge pas à la règle. Quelle chance hein?
J'avais envie de tester un auto-déploiement Cloud, sans serveur, toussa toussa.
J'ai toujours regardé fort de travers tout ce qui tourne sur Heroku, principalement parce que dès que j'accède une URL sur Heroku SA MARCH PO.
Ou alors ça tourne dans le vide pendant plusieurs minutes.
J'ai décidé de me tourner vers Redhat OpenShift, qui utilse Kubernetes pour orchestrer des containers Docker.
Ils ont un plan gratuit.
J'ai déjà parlé quelques fois de Spring Boot, qui va me permettre d'emballer ma classe de pseudonymisation dans un web service avec moulte.s facilité.s.
De plus, par nature, Java va emballer toute l'application dans un fichier jar, ce qui est bien pratique pour intégrer mon dictionnaire qui, je le rappelle, est un fichier texte.
Le déploiement sur OpenShift
Vous devez commencer par créer un compte (NOOOOOON, sérieux?).
En choisissant le plan gratuit pour les pauvres, il devrait vous assigner à un datacenter et vous fournir l'accès à la "Web Console".
En prérequis, il faudra que votre appli Spring Boot soit sur un dépot Github (accessible publiquement, si vous ne voulez pas vous encombrer avec des clés et des bidules machins). Vous ne devez pas pousser le projet compilé sur Github, le but étant qu'OpenShift compile lui-même votre application avec Maven (ou Gradle je suppose).
Ensuite, vous pouvez créer un nouveau "projet". La super "web console" se traine parfois à mourir, c'est normal. C'est génial Docker, je vous jure (lule).
Et là vous sélectionnez OpenJDK 8:
J'avais essayé de déployer sur Wildfly (serveur d'application) mais ça fonctionne moyennement. Ouais en fait ça fonctionne pas du tout. Mais il ne donne pas d'erreur et Maven a l'air de compiler normalement, donc je ne suis pas certain de ce qu'il se passe.
Etant donné que par défaut, Spring Boot compile en incluant un Tomcat intégré, j'imagine que c'est mieux de simplement créer une appli Java.
Vous devrez remplir quelques options de configuration:
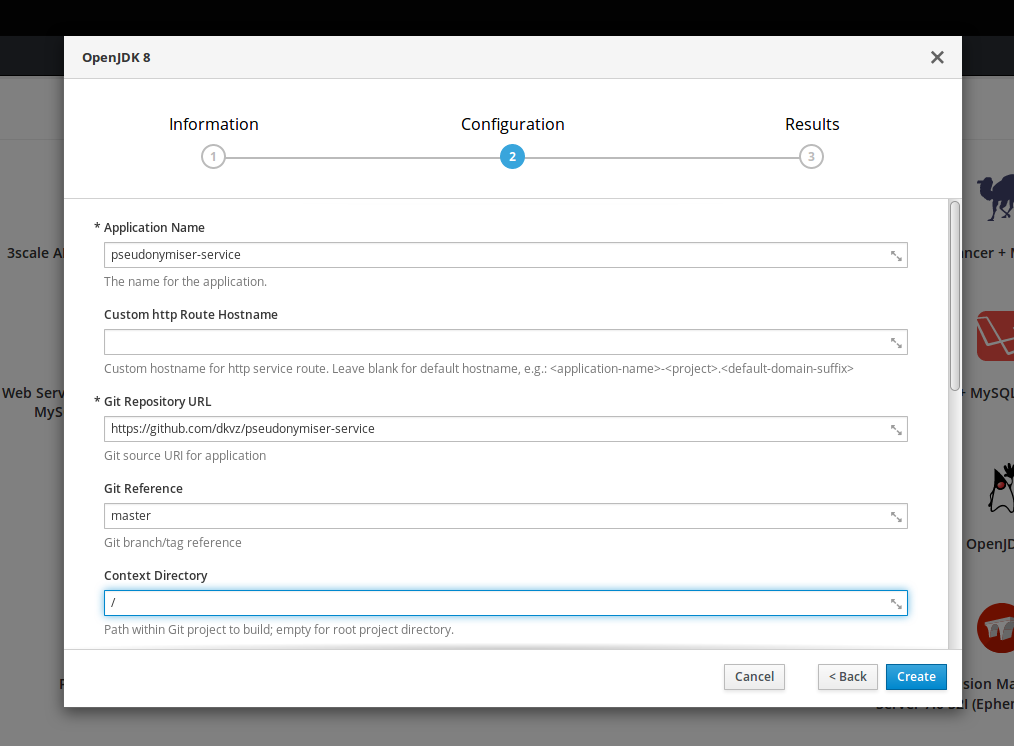
En particulier, votre répo Git, qui ne doit pas nécessairement être sur Github, en fait, et il semblerait qu'il soit possible d'utiliser SSH. Mais le plus simple c'est un répo publique sur Github en HTTP.
Il s'agit également de modifier le "Context Directory" en "/" parce que par défaut c'est un truc improbable.
Ensuite vous cliquez "créer", et puis des choses se passent. Oh oui, des choses se passent. Une image Docker est créée sur le Docker Registry d'OpenShift, peut-être pour y rester pour toujours. Votre croutte programmée restant collée quelque part au fond des nuages pour l'éternité. C'est beau. J'adore Docker.
Si tout se passe bien, il devrait vous annoncer que votre appli est disponible avec une route en HTTP et une URL bien courte comme on les aime:
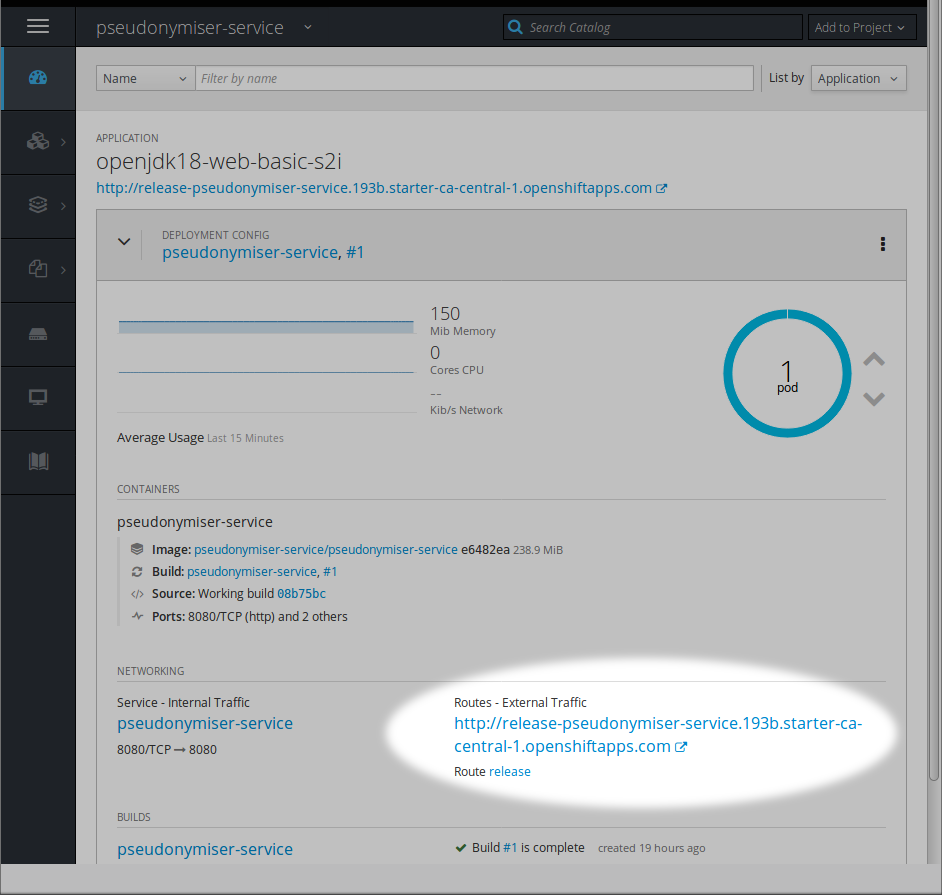
Et alors, ça fonctionne?
Ben... C'est exactement comme Heroku en fait. Le projet "s'endors" quand il n'est pas utilisé ou quand vous faites une modification. Vous avez alors une jolie page grise qui dit que votre "POD" est pas démarré, est pourri, n'a pas de routage, ou bien Docker a fait une mise à jour et plus rien ne fonctionne et c'est pas leur faute:
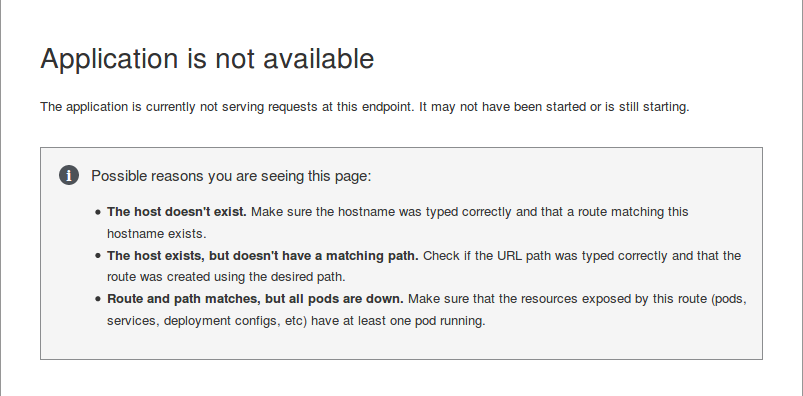
C'est trop cool le SERVERLESS, tellement facile et magique. Wow quoi.
Si tout se passe bien, ça pseudonymise, CLIQUEZ-MOI. Faut juste un peu insister avec F5 parfois.
Remplacez simplement le texte dans l'URL pour pseudonymiser autre chose.
Peut aussi renvoyer du JSON (??)
Conclusion
Je ne suis pas convaincu.
Et accessoirement il y a une erreur pour mettre à jour mes métriques.
Retrouver le projet sur Github
Pour finir, vous pouvez trouver le projet Spring Boot objet de cet article ici:
Commentaires
Il faut JavaScript activé pour écrire des commentaires ici