

C'est quoi ce titre?
On est en janvier, j'ai le droit.
Introduction
Comme je disais déjà dans cette brève, pour moi la finalité de JavaScript (affectueusement abrégé "JS" pour la suite de cet article) résidait dans l'ajout de petits morceaux de code pour afficher un petit calendrier qui permet de choisir une date, ou pour ouvrir une fenêtre popup.
Quand tous les navigateurs ont commencé à massivement bloquer les fenêtres popup... Ben ça servait plus que pour faire un date picker. Je suis désolé je ne vois pas d'autre utilisation.
Le web 2.0 n'est pas de mon avis, et la révolution de l'AJAX (plus personne n'utilise ce terme de vieux) et des réseaux sociaux sont à l'origine d'une demande massive pour du web plus réactif avec moins de génération côté serveur avec notamment l'idée d'absolument devoir afficher quelque chose à l'utilisateur pendant que l'énorme timeline bourrée de publicités et de mentions que Facebook va devenir payant et qu'il faut poster une déclaration de propriété intellectuelle sur son mur est téléchargée en arrière-plan.
C'est seulement en 2016 que j'ai commencé à m'intéresser à ces FRAMEWORKS JS dont tout le monde parle. Je me souviens, Angular 2 venait tout juste de sortir.
C'est un vrai langage sérieux le JavaScript?
Mis à part le côté "lel JS c'est pas un vrai langage" que je ne vais pas m'abaisser à discuter ici, une caractéristique ancestrale de JavaScript c'est que les gens l'utilisent rarement tel quel.
La tendance générale a toujours été d'ajouter au moins une occurence d'un genre de couche ou abstraction au dessus du langage.
Je vais pas unilatéralement cracher sur cette pratique, parce qu'elle a l'avantage de permettre d'utiliser le même code sur plusieurs navigateurs qui présentent des implémentations différentes de JavaScript, et ça, à l'époque glorieuse d'Internet Explorer, c'était plutôt important.
Aujourd'hui, c'est moins important. Internet Explorer a fini par disparaître, non sans atroces souffrances, suivi par son successeur Edge qui est maintenant basé sur Chromium, la base Open Source de Chrome. Nous sommes dans une toute nouvelle ère de fraîcheur encore jamais atteinte.
D'aucuns vous diront que la mise en concurrence de plusieurs implémentations de JS a permis de tirer le maximum en performances et innovations. Moi je vous dirais surtout qu'on se tape des dizaines d'années d'évolution de langage et que même dans le monde de Node on est, encore aujourd'hui, plus ou moins obligé de publier le code de production en vieux JS tout moisi de 2010.
Un thème récurrent consiste donc à toujours essayer de plier JS pour lui faire faire des trucs qui ne sont pas prévus au départ. Pratique qu'on appelle couramment hacking (détourner l'utilisation de quelque chose).
Un peu comme si vous avez reçu une machine à laver qui se charge par le dessus, mais ça fait chier parce qu'en fait vous aimeriez bien la charger par le côté donc vous faites un énorme trou sur le côté. Mais euh... Vous êtes maintenant face à un petit soucis: le tambour tourne dans le mauvais sens. Pas grave, on peut tout démonter et remonter à l'envers et translater toutes les commandes du microcontrôleur en compilant tout en une cible intermédiaire. Tant qu'on y est on va aussi installer un porte-gobelet articulé qui a pour prérequis d'ajouter un bras en acier qui a pour dépendance un socle ancrable sur la machine à laver qu'il va falloir forer sur le bâti. On découvrira plus tard que sur certains modèles obscurs de machine à laver, la fixation du socle ancrable nécessaire au bras articulé qui soutient le porte-gobelet s'avèrera être la cause d'une fuite de l'arrivée d'eau due à une dimension de forage légèrement trop généreuse. Le problème c'est que le porte-gobelet est maintenant indispensable parce qu'il soutient aussi le mécanisme du contrôle vocal qui est nécessaire pour les personnes à vision réduite. Du coup on est un peu coincé avec la fuite.
C'est ça, JavaScript. En fait, c'est BEAUCOUP de hacking.
Cela étant, parfois j'ai vraiment du mal à comprendre pourquoi on essaye de le plier à faire certaines choses. C'est un peu comme aller trop loin en essayant de créer de nouvelles races de chien, ça n'est plus du tout clair que le chihuahua descend du loup.
A quoi ça sert JavaScript?
De nos jours on peut faire toutes sortes de trucs avec JS. Par exemple, tout.
Dans un navigateur c'est aujourd'hui possible d'accéder à votre webcam ou micro, analyser les données, dessiner dans un contexte 2D et 3D... Et en dehors du navigateur, tout ce qui est client/serveur, système de fichier et même embarqué entrent en jeu.
En fait il est vraiment nul ce titre parce que JS est un langage de programmation moderne et par extension-déduction-flexion, on peut pratiquement tout faire avec.
Les plus vieux d'entre-nous (càd ceux qui ont plus de 25 ans) savent que ça n'a pas toujours été comme ça.
A quoi ça servait avant JavaScript?
Je comptais totalement vous épargner l'histoire de la naissance du langage mais je vous livre tout de même une version courte (je vous jure):
JS a été chié en 10 jours dans le but d'offrir un langage de script pas trop difficile à apprendre et avec "Java" dans le nom (parce que c'était trop à la mode à l'époque — JS n'a aucun rapport avec Java mise à part leur part d'héritage commun du C) afin d'être en mesure de modifier dynamiquement des éléments des pages web ou permettre d'autres types d'intéractions dynamiques du côté du navigateur.
Ce sont là les racines du langage et le cas d'utilisation de JS le plus historiquement représentatif: les fonctions prompt() et alert().
Non je plaisante en fait c'est la manipulation du DOM au sein du navigateur.
Je vais certainement passer au dessus de tout un tas de concepts sans les expliquer dans cet article, mais prenons un peu de temps pour resituer cette histoire de DOM parce que c'est un pilier essentiel de JS et c'est là que la majorité des pliages du langage en origami foireux se produisent.
Pour tripoter le DOM, nous avons besoin de quelques éléments.
Tout d'abord, un NAVIGATEUR, comme celui-ci:
Ensuite, une ressource à ouvrir dans ledit navigateur qui soit au format (avec type MIME valide mais ne nous égarons pas) HTML.
Par exemple, nous pouvons sauver le contenu suivant dans un fichier test.html:
<html>
<head>
<title>DOMz</title>
</head>
<body>
<h1>It works! Je sais pas pourquoi j'ai écrit ça.</h1>
</body>
</html>Ouvrez ce machin dans votre navigateur, et pressez "F12" puis rendez-vous sur l'onglet "Inspecteur":
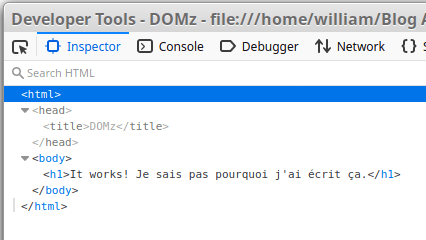
Vous voyez cette hiérarchie d'éléments qui commence avec un élément "html" comme parant global? C'est ça le DOM OKAY?
Le navigateur a lu le code HTML et a créé un modèle de document à partir de ce code. Votre code pourrait être totalement moisi et invalide que le navigateur s'affairerait tout de même créer un DOM du mieux qu'il le peut.
Reste plus qu'à introduire du JavaScript et voir si on peut tripoter le DOM depuis le code parce que ce serait quand même pas mal, quoi.
Ouvrons le fichier html créé précédemment dans Chrome ou Chromium parce que Firefox n'affiche pas la même chose et ça va ruiner mon exemple. De toutes façons je suis sûr que vous utilisez déjà Chrome MsieurDame-je-donne-toutes-mes-données-au-diable.
Il s'agit ensuite d'ouvrir les outils de dev (avec F12) puis afficher l'onglet console.
Nous allons maintenant récupérer un élément du DOM, et le modifier, EN LIVE.
Tapez les instructions suivantes dans la console pour que la magie opère:
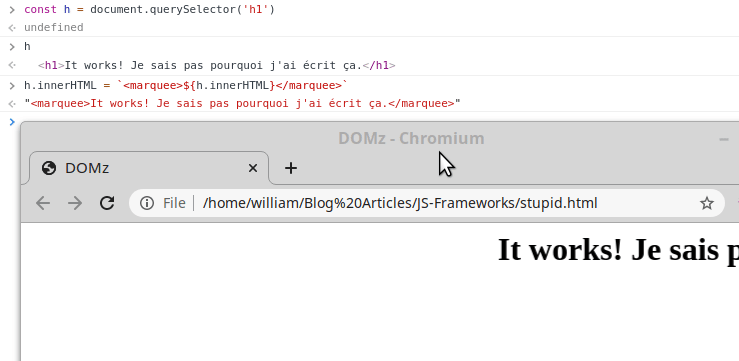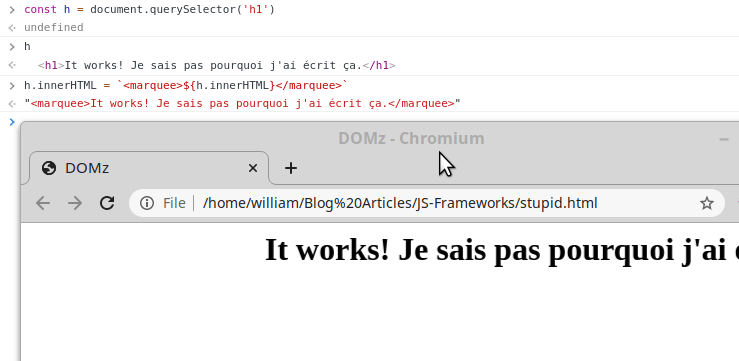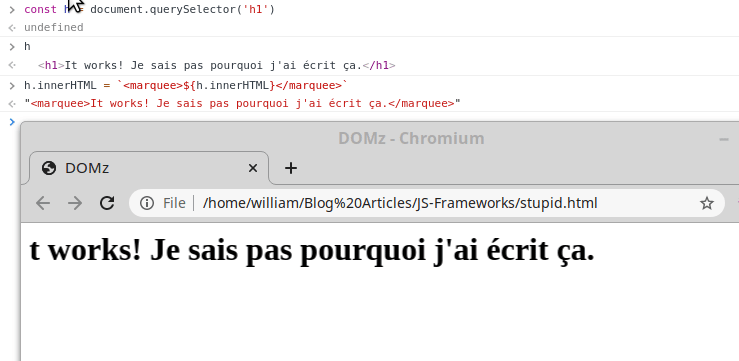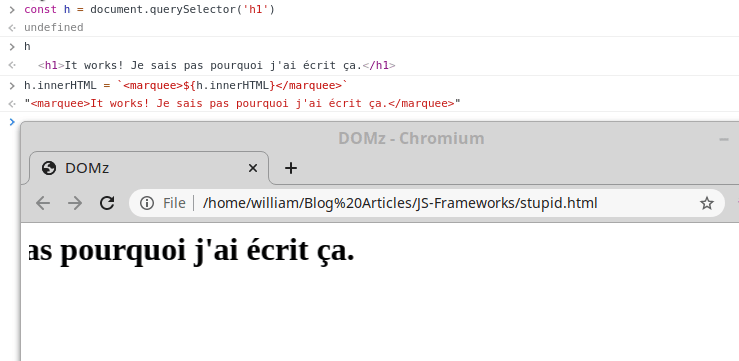
Dans le même genre, vous pouvez aussi hacker Google, oui, vous l'avez appris ici. C'est également cette technique qui permet de facilement créer de faux Tweets ou falsifier n'importe quoi sur le net:
L'API du DOM
Première chose à savoir (commencez à prendre des notes les gens du fond de la classe), traverser ou modifier le DOM passe par un obect global nommé document, comme vous pouvez le voir certains GIFs des sections précédentes.
Dans le très vieux DOM, il n'était possible que d'accéder à des éléments de type liens, images, ou contrôles de formulaires et les API de ces éléments étaient... Elémentaires. Très simples. Nulles.
Pour accéder au premier champ du premier formulaire, il eut été nécessaire d'écrire quelque chose du genre (NB: je pense que c'est toujours possible):
document.forms[0].elements[0]Au fil du temps, d'autres techniques pour parcourir le DOM en tant que liste de noeuds HTML sont apparues et les API des éléments se sont étoffées.
Le moyen le plus clair, unifié et évident de récupérer des données depuis le DOM (depuis un champ texte par exemple) ainsi que de modifier des données est apparu quelque part autour de IE 5.5 (le mémorable) et permet de récupérer un élément via son attribut "id":
const champEmail = document.getElementById('email');Qui nous permet de récupérer une référence à un hypothétique champ texte arborant l'identifiant "email".
Vous pouvez maintenant faire tout un tas de trucs avec:
// Récupérer la valeur:
const texte = champEmail.value;
// Modifier la valeur:
champEmail.value = texte + ' Modifié';
// Cacher le champ:
champEmail.style.display = 'none';
// Etc.Récupérer un élément par son attribut "id" est une chose. Tant qu'on y est, pourquoi ne pourrait-on pas récupérer des éléments par nom de tag ou classe CSS?
Les deux méthodes existent effectivement:
document.getElementsByTagName('button');document.getElementsByClassName('title');C'est bien mais tant qu'à faire, il existe un autre moyen unifié de sélectionner des éléments dans le DOM pour appliquer des feuilles de style, ce serait trop bien si on pouvait l'utiliser en JS (oui, c'est la toute première mention de CSS-in-JS je suppose).
Ces machins-qui-servent-à-sélectionner-des-trucs s'appellent des sélecteurs.
Les sélecteurs CSS
Qu'est-ce que les CSS viennent faire dans cette histoire? Ca sert pas juste à mettre l'arrière-plan en rose les CSS?
Pouvoir récupérer les éléments par tag ou par ID c'est bien mais les gens commencent à se rendre compte que ce qu'on appelle "sélecteur CSS" porte plutôt bien son nom en terme de sélection de trucs et que ce serait plutôt pas mal de pouvoir utiliser ça pour récupérer des éléments du DOM.
Je me souviens que quand j'ai découvert les CSS, j'utilisais uniquement les sélecteurs "classe" et "tag" simples (donc comme si j'utilisais getElementsByClassName et getElementsByTagName mais en CSS) et j'ignorais totalement que ça s'appelait des sélecteurs.
Je l'ai ignoré pendant toutes mes études d'informatique aussi.
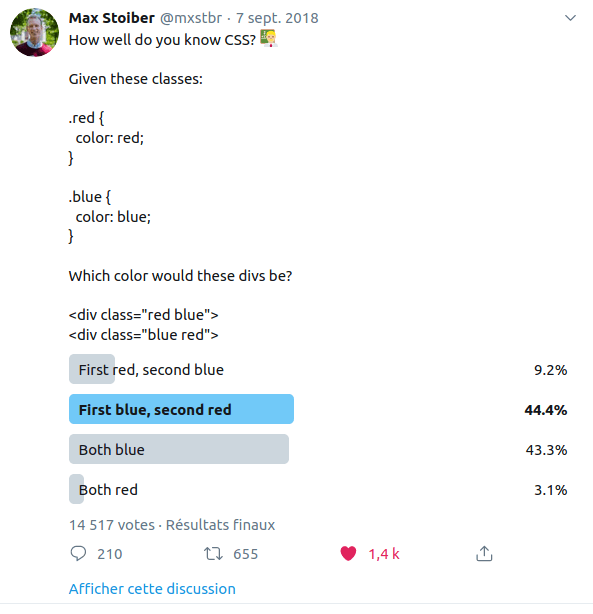
Je ne captais également rien à la CASCADE (système de priorité des CSS) mais ça on dirait que je ne suis pas le seul.
Pour illustrer, mes CSS ressemblaient à ça:
BODY { background: deeppink; }
.titre { letter-spacing: 20px; }Oui je mettais les tags en majuscule. Vous pouvez me juger je me juge aussi tout le temps.
Il paraîtrait qu'il existe même des preuves qui datent de cette époque glorieuse.
En fait, comparés à tout le système de priorités des CSS, les sélecteurs ne sont pas si compliqués à comprendre.
Par exemple, c'est évident que ceci:
div[data-lol=pantalon].header > span:nth-child(odd) {
color: deeppink;
}Sélectionne tous les éléments span qui sont enfants impairs directs de tous les éléments div qui ont comme class header et possèdent l'attribut data-lol qui a la valeur pantalon.
C'est clair au premier coup d'oeil.
Blague à part, les sélecteurs c'est vite le bordel surtout s'il faut essayer parfois de prévoir leur spécificité (????) qui est liée à cette fameuse CASCADE — Alors les gens ils ont essayé de mettre en place certaines conventions, comme BEM, qui consiste à utiliser majoritairement des classes CSS (qui ont priorité sur pas mal de choses (CASCAAAAADESDFKHDSFJKh) et utiliser les caractères "--" et "__" dans les noms pour leur donner un sens au niveau de la structure.
La première fois que j'ai vu des noms de class du genre main-header__message--state-success j'ai un peu vomi dans ma bouche mais aujourd'hui je dois dire que je comprends l'attrait.
Les noms de classe sont toujours horribles, mais au moins ça a un sens dans ma tête. C'est cool hein.
C'est plutôt pas mal de mettre tout ce qu'on peut en place pour rendre les CSS plus souples. C'est pas pour rien que tout le monde utilise SASS alors que ça double la taille des dépendances d'un projet Node et compile tout un tas de trucs étranges qui vous fait questionner l'essence même de pourquoi on ose appeler ça du "développement moderne".
Je suis fort désolé d'avoir ouvert une gigantesque parenthèse qui n'a rien à voir avec JS et qui veut globalement dire "LES CSS C'EST L'ENFER". Maintenant je suis obligé de la fermer (la parenthèse).
Non, mais, soyons sérieux une minute, qui s'est dit que c'était une bonne idée de ne pas autoriser les commentaires précédés de "//" en CSS? Non, on va juste autoriser /**/. POURQUOI??
Je suis sûr que c'est encore la faute d'IE 6 =+?#!à>@

Bon on a compris que les CSS c'était pourri, je ferme la parenthèse.
Reste que les sélecteurs CSS eux-mêmes sont assez balaises, imaginez que l'on puisse parcourir le DOM et récupérer des éléments en utilisant ces sélecteurs, ce serait super chouette hein?
C'est là que JQuery est arrivé.
Le cas JQuery
Quelque part autour de l'an de graisse 2006 apparaît une librairie JavaScript qui changera le monde, pour le meilleur et/ou le pire: JQuery. Le mythe. La légende.
Le but premier de JQuery est de pouvoir récupérer des éléments du DOM en utilisant des sélecteurs CSS. Voilà c'est tout. Mais c'est pas mal. A l'époque ce n'était pas possible nativement.
Ils ont également pensé à rendre le code moins verbeux dès le début, parce que des noms de méthode comme getElementById, ou pire, getElementsByClassName ça nous fait rapidement des km de texte.
Ces deux extraits sont équivalents, remarquez que celui qui utilise JQuery est plus court.
// Without JQuery:
let title = document.getElementById('title');
// With JQuery:
let title = $('#title');Si le début de votre code est constitué d'une dizaine de lignes "x = document.getElementByTrucMachinSaMere" ça fait vite long.
Entre nous, tant que vous êtes là et pour que vous ne soyez pas venus pour rien, je peux vous livrer une technique utilisée par les programmeurs d'élite pour avoir l'air hyper classe quand vous devez récupérer une série d'éléments avec les méthodes du DOM:
<html>
<head>
<title>DOMz</title>
</head>
<body>
<header id="header">
<h1 id="titre">It works! Je sais pas pourquoi j'ai écrit ça.</h1>
</header>
<main id="main">
<p>Coucou</p>
</main>
<script>
const [ titre, header, mainContent ] =
['titre', 'header', 'mainContent'].map(x => document.getElementById(x));
// Faire des trucs avec les variables.
</script>
</body>
</html>C'est peut-être pas toujours beaucoup plus court, mais c'est classe.
L'important c'est d'avoir l'impression d'écrire du code de qualité, tout est dans la tête.
JQuery avait encore un autre avantage. Oui je parle au passé parce que, je vous le dit tout de suite, JQuery c'est un peu mort, genre bien plus qu'écouter la radio ou se rendre chez le disquaire avec son handspinner.
L'autre intérêt majeur, c'est d'offrir une API unique pour manipuler le DOM à une époque où IE 6 et Microsoft en général rendent le développement web aussi anxiogène que si vous deviez opérer vous mêmes le glaucôme de votre grand-mère avec une bouteille de Jägermeister et une pince à épiler.
Parce que oui, on peut chier sur JQuery aujourd'hui si on veut mais n'oublions pas qu'à ses origines, il était une bénédiction pour ne pas devoir se soucier de la jungle de problèmes de compatibilité entre les différents navigateurs.
En résumé
JQuery permet de réaliser des opérations courantes sur le DOM de manière générallement moins verbeuse que nativement.
Il permet aussi de s'affranchir de devoir se tenir au courant de toutes les subtiles différences entre navigateurs. Ce qui n'est plus vraiment un avantage aujourd'hui puisque Internet Explorer a entièrement disparu (Edge est basé sur Chromium).
Il y a cependant un prix à payer pour l'utilisation de JQuery: le poids de la librairie et le temps nécessaire au navigateur pour parcourir et exécuter le code de la dite librairie.
J'ai personnellement un autre problème avec JQuery: au plus on l'utilise, au plus ça va être compliqué de s'en débarasser un jour, il faut réécrire tout le code.
Pourquoi il faudrait s'en débarasser? Le poids de la librairie et le temps d'exécution comme spécifié plus haut, mais aussi le risque en terme de sécurité. Toute dépendance est un risque en terme de sécurité, et surtout remplit votre boîte mail de notifications de Github comme quoi votre projet de mono-page statique est super vulnérable et c'est très chiant (oui je sais qu'on peut les désactiver mais je veux pas qsldkmfskljf).
La quantité de notifications de sécurité ne m'étonne que très moyennement, il y a un ou deux ans j'avais réalisé un reverse scroll des dépendances d'un projet qui utilise juste Webpack et JQuery:
Des librairies comme Bootstrap, même dans leurs dernières versions, sont toujours mariées à JQuery et ont énormément de mal à s'en débarasser [Insérer une blague sur l'institution sacrée du mariage].
En règle générale je ne suis pas très très fan des dépendances à outrance. Je pourrais vous mettre des memes à propos de ce bon vieux npm install.
Les progrès de la plateforme
De nouvelles méthodes natives pour récupérer les éléments du DOM en utilisant un nom de classe ou de tags ont fini par voir le jour, mais ça j'en ai déjà parlé. J'ai probablement oublié de dire que JQuery existait déjà avant ces méthodes.
Le progrès majeur était d'ajouter des méthodes pour récupérer des éléments à partir de sélecteurs CSS, càd l'équivalent du $('selecteur') de JQuery.
Par chance le nom est même assez concis:
- document.querySelector — Récupère 1 ou aucun élément;
- document.querySelectorAll — Récupère une liste d'éléments, qui n'est pas un array standard mais un objet obscur de type "NodeList" parce que sinon ce serait pas drôle;
Dans la console de Chrome et Firefox (et peut-être d'autres je sais pas trop), ils ont été jusqu'à ajouter une fonction "$" qui imite JQuery. Pour vous dire à quel point JQuery est légendaire.
Il y a des gens qui ont produit des tableaux de comment faire telle ou telle chose avec JQuery ou nativement. Par ex. ce site qui n'a toujours pas de HTTPS en 2019.
Au final, de nos jours, on a plus besoin de JQuery, et ce même s'il était hypothétiquement dépourvu des inconvénients évoqués précédemment.
Peut-on créer une app JS sans librairies?
Ha ben oui hein. Je sais que de loin il semblerait que JS soit tellement nase que personne ne l'utilise tel quel mais ça n'est pas (plus?) vrai du tout.
La programmation en JS pour les navigateurs est événementielle et impérative. Enfin moi je trouve.
Je vais vous guider dans la création d'une machine à sous JavaScript en hômage au premier projet qui était dans mon bouquin sur Visual Basic 6 à l'époque pré-internet-chez-moi.
J'ai réussi à retrouver une image du truc, c'était trop bien VB 6.
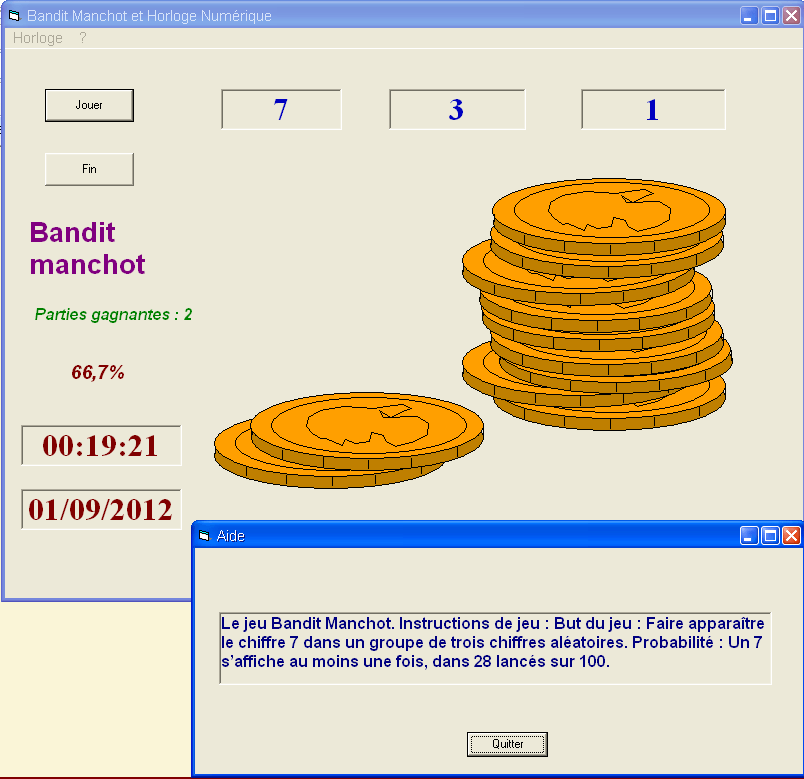
Il existe plus qu'une manière de s'y prendre pour arriver à ses fins. C'est toujours vrai en programmation mais c'est massivement vrai pour JavaScript.
L'interface / la vue
Il est de bonne pratique de commencer par créer une maquette de notre future interface.
Je parle de tout ça dans ma série extrêmement sérieuse sur la conception étape par étape de dessins vectoriels.
J'explique au cas où: le code de notre vue sera fait de HTML et CSS. Ces technologies sont hors contexte pour cet article et je ne devrais normalement pas m'étaler dessus si j'arrive à contenir ma tendance naturelle à l'étalage. L'étalation. L'étalement.
Le code de la vue est à priori indépendant du code "comportement" (le JS, quoi). Notons bien le "à priori" pour plus tard. No spoil.
Voici le code HTML de la partie intéressante:
<h1>Machine à sous moche 1.0</h1>
<main class="m">
<div class="panel slot-panel">
<div id="status"></div>
<p>Le truc à droite est un levier (je suis pas un artiste).</p>
<div class="slots">
<div></div>
<div></div>
<div></div>
</div>
</div>
<button id="leverBtn" aria-label="Abaisser le levier!" title="Abaisser le levier!">
<svg viewBox="0 -3 20 100" aria-hidden="true">
<line x1="10" y1="10" x2="10" y2="90" stroke="#444" stroke-width="2" />
<circle cx="10" cy="10" r="5" fill="red" />
</svg>
</button>
<div class="panel">
<div class="buttons">
<div>Cash: <span id="cashLabel">$0</span></div>
<div>Mise: <span id="betLabel">$0</span></div>
</div>
<div class="buttons mt-1">
<button id="betAddBtn">Miser+</button>
<button id="betRemoveBtn">Miser-</button>
<button id="resetBtn">Réinitialiser</button>
</div>
</div>
</main>Tour du propriétaire rapide: On a un titre qui fait rien, un div vide avec l'ID "status" qu'on va utiliser pour dire si c'est gagné ou pas, un super levier en SVG (évidemment) dans un bouton et un panneau avec des éléments span pour afficher l'état actuel de vos finances ainsi que quelques autres boutons pour augmenter ou réduire la mise, et relancer le jeu.
J'en arrive au magnifique résultat ci-dessous, dont le niveau de kitchitude est intentionnel. Je suis au courant que c'est un peu raté sur la plupart des mobiles mais j'ai pas le temps de tout refaire. Il y a plus de chances que ça passe en plein écran.
Je vous le dis déjà au cas où je l'oublie plus tard, le code de présentation de base et les styles sont également disponibles sur Github.
Le code
Le plus simple est de poser le code JS juste avant le tag de fin <body> ; histoire d'être certains d'avoir le DOM chargé avant l'exécution du JS.
Examinons quelques différentes philosophies de mise-en-place dans les sous-sections ci-dessous.
On va faire simple d'abord, et on parlera de testabilité, d'injection de dépendance et de graisse saturée plus tard, okay?
La voie de l'impératif
Note importante de l'auteur: la notion d'impératif en programmation est toujours relative. Comme beaucoup de choses dans beaucoup de domaines.
Sachant que JavaScript est un langage fonctionnel et que nous sommes dans un paradigme événementiel. Mais si j'ai envie de dire impératif, je peux, parce que c'est mon blog et j'ai raison.
Laissez moi vous expliquer d'emblée comment nous allons procéder:
- Récupérer tous les éléments dont on a besoin et les mettre dans des variables;
- Initialiser les éventuelles variables d'état et leurs valeurs initiales;
- Assigner des fonctions aux événements d'interface à gérer.
Petit constat: nous ne touchons pas du tout à la partie présentation. En suivant la voie de l'impératif, elle reste indépendante.
Tout ce qui est comportement est attaché lorsque le DOM est chargé, et que le JS s'exécute.
Ceci signifie que si JS est désactivé dans le navigateur, on aura une série de vieux boutons qui font rien quand on clique dessus.
C'est grave? Non. Mais c'est pas optimal.
Cette approche de tout initialiser après est commune pour les "frameworks CSS", comme Materialize, Bulma, Foundation, etc. Ils fournissent générallement une fonction JS à appeler lorsque le DOM est chargé pour que les éléments dynamiques comme les menus puissent fonctionner correctement.
Examinons dans l'ordre le code que j'ai forcé hors de ma personne pour illustrer l'approche impérative.
Récupérer tous les éléments du DOM:
const [
leverBtn,
cashLabel,
betLabel,
betAddBtn,
betRemoveBtn,
resetBtn,
status
] = [
'leverBtn',
'cashLabel',
'betLabel',
'betAddBtn',
'betRemoveBtn',
'resetBtn',
'status'
].map(x => document.getElementById(x));
const slots = document.querySelectorAll('.slots > div');J'utilise ici à la fois ce bon vieux getElementById ainsi qu'un sélecteur CSS. Je pense qu'il y a des arguments à n'utiliser que querySelector et querySelectorAll parce qu'ils sont peut-être plus rapides.
J'aime bien continuer à utiliser getElementById parce que c'est plus compatible et qu'historiquement c'était aussi plus rapide, à l'heure d'aujourd'hui je sais pas trop, mais prout.
Je définis ensuite quelques constantes, puis j'initialise les variables d'état, ici dans un objet qui s'appelle state parce que j'aime bien insister sur l'idée que c'est pas React qui a inventé cette histoire.
let state = {
cash: startMoney,
bet: startBet,
positions: [0, 0, 0],
yPositions: [0, 0, 0],
prevPositions: [0, 0, 0]
};Je dois ensuite manuellement (important) mettre à jour l'affichage, tout du moins pour la mise actuelle et le total en banque, en utilisant une méthode déclarée ou importée auparavant (ou pas, il y a toujours le HOISTING ou encore hissage mais n'entrons pas là dedans s'il vous plait):
updateUI(state, cashLabel, betLabel);Le cours normal d'un développement impératif continue avec la déclaration de tous les événements:
leverBtn.addEventListener('click', () => {
// STUFF
});
resetBtn.addEventListener('click', () => {
// STUFF
});
betAddBtn.addEventListener('click', () => {
// STUFF
});
betRemoveBtn.addEventListener('click', () => {
// STUFF
});Après les déclarations d'événements se trouvent parfois des clauses du genre "démarrer ceci" ou "montrer cela" ou tout simplement "OK lance l'application maintenant!" ou "démarre le routage!". Vous avez compris (?).
En résumé, l'interface (HTML/CSS) est dans ce cas-ci totalement indépendante du JavaScript qui à son tour récupère des éléments choisis et ajoute tout le comportement dynamique par après.
Vous sentez des vibrations un peu artisanales? Non? Bon, tant pis.
Le code impératif peut s'appliquer à n'importe quel code de présentation, y compris celui qui a été généré par un script. Il suffit de le lancer une fois que le DOM est modifié, il récupère tous les éléments qui le concernent, et les enrichit d'un comportement.
La voie du déclaratif mais un peu foireux
Avec l'approche impérative, ce n'est pas immédiatement clair que cliquer tel bouton exécute telle fonction.
Dans mon exemple j'utilise des boutons pour toutes les interactions mais on pourrait avoir toutes sortes d'autres événements: cliquer à un endroit précis de l'écran, recevoir du glisser/déposer, etc. C'est impossible de voir au premier coup d'oeil que telle zone de l'interface est destinée à remplir telle fonction.
Il faut chercher le addEventListener idoine dans le code, sachant qu'il pourrait même en exister plusieurs pour le même éléments, ils pourraient être ajoutés dynamiquement à un moment particulier, retirés plus tard, ... Il est même possible d'ajouter un écouteur d'événement à usage unique.
En résumé, l'impératif est très puissant et flexible mais pas très clair.
Plutôt que d'utiliser addEventListener ou équivalent sur une référence d'un noeud du DOM qu'il aura fallu récupérer préalablement, il est possible d'attacher une fonction à événement sur un élément directement dans le code HTML.
Le code présentation n'est du coup plus vraiment indépendant. Les gens préfèrent donner cette concession pour obtenir le gain en clarté et le lien évident entre éléments d'interface et fonctionnalité.
La mode est donc actuellement très largement du côté du déclaratif. Un peu comme le XAML en .NET (remarquez qu'ils commencent même l'article par XAML est un langage déclaratif histoire de souligner que je ne raconte pas que des conneries) ou encore le FXML de JavaFX, où on utilise des bindings et des déclarations de méthodes d'événement directement dans le code de présentation.
Les fameux FRAMEWORKS et autres librairies comme React ou Vue sont tous déclaratifs.
Je pense que certains ignorent qu'il est possible d'écrire ce type de code sans aucune dépendance et autre libroframework en utilisant juste des vieux attributs HTML couverts de champignons qui existent depuis 1000 ans tels que onclick, onsubmit, etc.
Alors, d'accord, qu'on se le dise tout de suite, ça sent le vieux et c'est de là que vient le nom de la section qui nous occupe.
Il y a également une autre raison qui fait que ça pue: les méthodes mentionnées dans les attributs HTML doivent absolument exister dans la portée globale. Si vous ne comprenez pas de quoi je parle, c'est pas grave on en parle plus loin.
Le code du template est très similaire mis à part les déclarations de fonctions d'évènement. Exemple etrait du code:
<div class="buttons mt-1">
<button onclick="addBetClick()">Miser+</button>
<button onclick="removeBetClick()">Miser-</button>
<button onclick="resetClick()">Réinitialiser</button>
</div>Ces fonctions n'existent pas encore et, comme mentionné précédemment, devront être accessibles dans la portée globale.
Dans un navigateur, l'objet qui contient toutes les variables globales s'appelle window.
En pratique, toute l'API du navigateur est quelque part dans window. Par ex. document est en fait window.document.
Ecrire du JS directement hors d'une fonction signifie que tout se retrouve attaché à window. Celà étant, pour mes exemples, j'utilise un module bundler qui me force à déclarer explicitement ce qui doit être dans la portée globale. C'est un peu compliqué et je reparle de toute cette histoire de portée globale plus loin, retenez simplement que, si vous avez l'intention d'utiliser la portée globale, assigner explicitement ce qui doit s'y trouver est une bonne pratique (attention que beaucoup vous diront que mettre quoi que ce soit dans la portée globale est une mauvaise pratique mais ça c'est une autre histoire et ce paragraphe est beaucoup trop long et je suis désolé).
Pour avoir facile à exposer les choses pour du debug éventuel (parce que ce qui est dans l'objet window est directement accessible dans la console JS du navigateur) j'ai tendance à grouper les variables d'état et la fonctionnalité dans un objet JavaScript.
J'aurais très bien pu faire ça pour l'exemple impératif également, d'autant plus que ce groupement permet de séparer du code, éventuellement le placer dans un autre fichier, créer une librairie, ajouter de l'injection de dépendance et rendre tout bien plus testable. On en reparlera.
Pour mon exemple j'ai TOUT mis dans un objet appelé app.
Créer un objet gigantissime qui contient tout est rarement une très bonne idée, c'est bien mieux d'importer séquentiellement des morceaux qui ont une fonction bien précise, mais pour une petite application, la pratique de l'objet géant est un grand classique dkvz.
Cette fois-ci, les variables d'état sont dans cet objet app et, comme on peut le voir dans le code, j'utilise une méthode pour créer l'état initial:
app.initialize();Ensuite les fonctions qui sont déclarées dans le code de présentation sont associées à des méthodes de l'objet app:
// Create the event handler functions:
window.resetClick = app.reset.bind(app);
window.leverClick = app.play.bind(app);
window.addBetClick = app.betAdd.bind(app);
window.betRemoveClick = app.betRemove.bind(app);Remarquez que j'utilise ce bon vieux bind() à chaque fois.
Je vais ouvrir une parenthèse pour essayer d'expliquer ça le plus rapidement possible (je vous jure): JS est un langage fonctionnel, càd qu'il est nativement possible d'assigner une fonction à une variable, les passer en paramètre etc. Alors, je sais que maintenant c'est aussi possible dans des langage basés sur des classes comme Java et C# mais pas sans un artifice infâme où le langage doit créer une fausse classe secrête pour contenir la fonction. En JavaScript c'est une partie intégrale du langage.
Le mot clé this en JS a une signification un peu différente de c elle qu'il aurait dans un langage basé sur des classes. Effectvement, si j'ai une méthode de mon objet app qui modifie des propriétés du même objet app, mais que j'assigne cette fonction à une variable (comme window.addBetClick par ex.), le contexte de app est totalement perdu, on a détaché la fonction et la sgnification du mot clé this dans la fonction a changé.
Le rôle de bind() est de générer une nouvelle fonction dont le contexte this a été forcé d'être celui donné en paramètre de bind.
JavaScript.
Je sais que je n'ai pas encore parlé de React, mais avant qu'ils n'essayent de faire passer un artifice d'écriture de fonctions flêchées comme membres de classes et avant qu'on passe presque exclusivement aux hooks (situation actuelle), il n'était pas rare de voir ce genre d'horreur au début d'une déclaration de composant:
class App extends Component {
constructor(props) {
super(props);
this.openClicked = this.openClicked.bind(this);
this.saveClicked = this.saveClicked.bind(this);
this.notImplemented = this.notImplemented.bind(this);
this.closeTagsModal = this.closeTagsModal.bind(this);
this.setEditorRef = this.setEditorRef.bind(this);
this.metaChanged = this.metaChanged.bind(this);
this.isArticleValid = this.isArticleValid.bind(this);
this.getArticle = this.getArticle.bind(this);
this.newArticle = this.newArticle.bind(this);
this.newClicked = this.newClicked.bind(this);
this.setArticle = this.setArticle.bind(this);
this.resetEditors = this.resetEditors.bind(this);
this.setModifiedAndFilename = this.setModifiedAndFilename.bind(this);
this.getOpenedFilename = this.getOpenedFilename.bind(this);
this.onEditorInput = this.onEditorInput.bind(this);
this.processSearch = this.processSearch.bind(this);
// MORE STUFF...
}
// REST OF ZE CLASS
}JavaScript.
Denière remarque: le style impératif se prête bien à l'usage de fonctions anonymes (comme les fonctions fléchées) alors que le style déclaratif se prête bien à tout ce qui est bien clairement déclaré et nommé.
Dernière remarque promis: plutôt que d'utiliser bouton.addEventListener pour ajouter des événements click à mes boutons dans l'exemple "impératif", j'aurais pu utiliser bouton.onclick = uneFonction. C'est le même effet, juste qu'en impératif il n'y a pas de raisons de ne pas utiliser addEventListener qui est plus puissant en terme de fonctionnalités et permet d'attacher plusieurs fonctions sur le même événement - ce type de gymnastique n'est générallement pas possible dans la programmation déclarative.
Aspects problématiques
Discutons les quelques problèmes partagés ou pas par les deux approches présentées ci-dessus.
Pollution de portée globale
J'avais dit qu'on allait parler de portée globale, j'ai déjà probablement déjà tout expliqué auparavant mais on va se le refaire.
Ce problème touche surtout l'approche déclarative que j'ai présentée et est une des raisons pour lesquelles j'ai ajouté le "un peu foireux" dans le titre.
Pour ceux qui s'y connaissent un peu, on pourrait penser que toutes mes variables de l'exemple impératif sont aussi dans le contexte global. Ce qui serait le cas si je n'utilisais pas de module bundler, mais j'en utilise un, et il place automatiquement le code dans une construction très typique de JS qu'on appelle une IIFE.
C'est quoi une IIFE? Très content que vous posiez la question, très valorisé hypothétique lecteur.
Une IIFE c'est une fonction anonyme qui s'exécute tout de suite.
En JS, les fonctions créent leur propre portée de variable, en incluant automatiquement les variables de la portée supérieure en closure. Si vous n'avez rien capté à cette seconde partie de la phrase, faites comme si elle n'était pas là.
Ce qui est déclaré dans un tag <script> et qui n'est pas dans le corps d'une fonction est attaché au contexte global, window (s'appelle global en NodeJS, ce qui est bien plus clair que window soit dit en passant).
Donc la solution pour ne pas tout mettre dans le contexte global... C'est de tout mettre dans le corps d'une fonction. Simple, non?
Pour faire au plus simple on déclare dès lors une énorme fonction anonyme, que l'on appelle immédiatement. Exemple:
;(function () {
// METTRE TOUT VOTRE CODE ICI
let variable = 'Pas disponible dans le contexte global.';
})();J'entends bien que pour quelqu'un qui commence le JS, ça ressemble à un gros hack maléfique cette histoire d'IIFE. Et c'est en grande partie parce qu'il s'agit d'un gros hack maléfique.
JavaScript.
La bonne nouvelle c'est que, comme j'expliquais plus haut, l'ajout d'IIFE est automatique quand vous utilisez un module bundler donc tout va bien.
A noter que certaines librairies, dont le légendaire JQuery, se mettent volontairement en portée globale.
Les scripts qui utilisent JQuery s'attendent à avoir une fonction nommé "$" accessible de partout. C'est à dire qu'il s'agit de window.$.
Les raisons pour lesquelles on évite de polluer le contexte global sont simples: le risque de collision de noms est le principal, un autre soucis mineur est que les éléments qui sont dans le contexte global sont accessible dans la console JS du navigateur. Vous avez peut-être du mal à voir pourquoi c'est un problème, mais une personne mal intentionnée pourrait accéder à des informations de session sensibles dans la console JS du navigateur de quelqu'un d'autre.
Conclusion: Il faut éviter de mettre des trucs dans le contexte global.
Tolérance faible au JavaScript désactivé
D'emblée et pour les deux approches présentées, le code ne prend pas en charge le cas où le JavaScript serait désactivé dans le navigateur du visiteur.
On verra comment mitiger ça plus tard.
Pour l'exemple déclaratif il y a un problème conceptuel avec l'ordre des opérations. En effet, on associe à des événements des fonctions qui ne sont pas encore déclarées. Pour bien faire il faudrait les déclarer avant de les mentionner dans le code de présentation, ce qui impliquerait de tout mettre dans <head> sauf qu'alors on est obligés d'attendre le chargement complet du ou des scripts avant de pouvoir afficher le DOM.
En plaçant le script à la fin de <body>, on peut déjà afficher l'interface avant que le code JS ne soit téléchargé mais ça signifie également que si le script fait 4 MB et qu'on est en Edge sur une autoroute Bulgare, il va y avoir une période de temps où cliquer sur les boutons de l'interface va soulever des erreurs, parce que les fonctions associées aux événements n'existent pas encore.
C'est pas extrêmement grave vu que ça se répare tout seul quand le script est téléchargé, mais ça peut faire moyennement sérieux.
Dans tous les cas, il est possible de se retrouver avec des boutons-qui-ne-font-rien, même si JS est activé puisqu'il est possible que le chargement soit anormalement long et que l'interface s'affiche avant l'exécution du JS.
Les "frameworks" attachent générallement le code de présentation au moment de la lecture du JS. C'est-à-dire qu'il n'y aurait par exemple pas de bouton dans l'interface au niveau du code de présentation parce que JS est censé les ajouter par la suite.
Cette manière de travailler va de paire avec l'idée de découper une application en "composants". Les composants comprennent à la fois le code de présentation (y compris les CSS en général) ainsi que leur code de comportement, et on attache le tout au moment de l'exécution.
C'est effectivement une solution à notre problème, mais il ne faut pas croire qu'utiliser des composants est la seule solution.
Une variation simple serait de placer tous les éléments interactifs en display: none; via les CSS, et de changer tout ça à la fin de tout le JS qui doit s'exécuter. En soi c'est juste un peu de code à ajouter.
A l'essentiel, ça pourrait consister à masquer la totalité de l'interface sauf le titre par exemple, jusqu'à ce qu'on soit à la fin du code JS, et là on affiche tout.
Difficile à tester
Là, on arrive dans les vrais sujets des vrais professionnels du développement: les tests!
L'explosion de l'open source a progressivement rendu les tests (particulièrement les tests "unitaires") comme élément de toute première importance pour tout projet sérieux qui se respecte (lire: pas pour mes projets, quoi).
Quand je suis sorti de l'école, je n'avais jamais écrit un seul test (je suis à peu près certain qu'aucun de nos profs n'a même évoqué le concept) alors qu'aujourd'hui les gens ont l'air d'apprendre ça en premier.
Je suis vieux. Mais ça on le savait déjà.
Un code bien testable est saucissonné en unités logiques pas trop épaisses, ce qui est une motivation majeure derrière le découpage classique en "composants" qu'utilisent tous les frameworks.
Il s'agit également d'utiliser des librairies bien claires avec une API bien documentée qui font usage d'injection de dépendance.
Pour celui qui débarque ça fait super peur ce terme, surtout quand ils écrivent des articles avec des grosses aiguilles comme image, mais en fait c'est assez simple.
Notre code, par exemple, utilise l'oject document et en a besoin dans le contexte global.
Pourtant, document n'existe pas si l'exécution se passe dans NodeJS.
Ce serait intéressant de pouvoir tester ce code sans avoir accès au vrai objet document, en utilisant des artifices de test comme les fakes, mocks et tout ce genre de choses.
Injecter un object nécessaire dans le code (une "dépéndance") depuis l'extérieur est appelé injection de dépendance. Depuis l'extérieur signifie générallement qu'il est passé en paramètre d'une fonction ou d'un constructeur par un machin bidule automatique parfois appelé framework ou conteneur d'injection de dépendance.
Les frameworks JS offrent des moyens de ne jamais devoir passer par l'oject document et fournissent l'API nécessaire à la manipulation des éléments du composant en cours.
De plus, ils ont toujours des constructeurs ou des moyens d'y importer des librairies qui, générallement par vertu du module bundler qu'ils utilisent, permet de n'importer ce code qu'une seule fois même s'il est utilisé par plusieurs composants.
L'exemple "impératif" décrit plus haut utilise des fonctions déclarées au début du code qui prennent tout ce qu'ils utilisent en paramètre. Ceci pourrait permettre de sortir ces fonctions dans une librairie externe, et de tout tester avec des mocks.
Le plan de tout mettre dans un énorme objet appelé app, comme dans l'exemple déclaratif (bien que ça aurait pu être utilisé dans l'autre exemple aussi) permet de le construire ou l'initialiser en lui fournissant toutes les dépendances internes qu'il utilise, l'objet devient alors beaucoup plus facile à tester.
Si toute cette affaire n'est pas très claire pour vous, c'est vraiment pas très grave. Moi je vous dirais bien qu'on s'en fout des tests mais je dois un peu en parler parce que c'est une motivation majeure à utiliser un framework et selon certains une raison suffisante à elle-seule: le gain en testabilité.
C'est pas "réactif" ton truc
La programmation événementielle et déclarative c'est bien mais pas suffisant pour atteindre l'illumination finale.
Il manque un truc qui est considéré comme essentiel (moi je trouve pas mais on m'a pas demandé mon avis): le côté réactif.
C'est quoi cette histoire de "réactif"? C'est un peu lié au concept de MVVM ou Model-View-Viewmodel.
Oui là on est en train de s'enterrer dans les vrais concepts d'abstraction du bonheur pour les vrais professionnels de l'informatique.
Ca m'étonnerais pas vraiment si un jour on en arrive au MVCMVVVdtoMM ou le modèle vue contrôleur vue vue vue (dto) modèle mainframe, mais tentons de nous limiter au niveau actuellement raisonnable de ridicule acronymistique.
Pour l'instant, je dois écrire manuellement la glu entre mes variables d'état et leur affichage sur l'interface/la vue ou leurs éventuelles conséquences comme afficher/cacher/désactiver des éléments de l'interface.
Par exemple, cliquer sur le bouton pour augmenter la mise dans notre application exemple fait appelle à une méthode qui met l'interface à jour:
betAddBtn.addEventListener('click', () => {
state.bet += 5;
updateUI(state, cashLabel, betLabel);
});La magie séductrice d'un framework JS est sa "réactivité", qui vous dispense de manuellement appeler une fonction telle que updateUI dans mon exemple lorsque vous modifiez une variable d'état comme state.bet, la mise-à-jour de l'affichage se ferait automatiquement.
En gros, le framework s'occupe de cette glu pour vous d'après ce que vous avez déclaré dans le code de votre composant (parce que les frameworks découpent toujours en composants et sont toujours déclaratifs, je rappelle).
Le framework offre également un endroit prédéfini pour y mettre toutes vos variables d'état. Ce qui est important puisqu'il doit détecter chaque fois que vous modifiez ces variables.
L'état représente le MODELE DE VUE dans le MVVM, qui inclus également l'idée que modifier une variable du modèle de vue doit modifier la vue en conséquence.
D'autres systèmes d'interfaces graphiques appellent ça des "bindings" (j'y consacre une énorme section dans article sur JavaFX, et ça existe aussi en .NET/WPF).
Au début de la folie du framework, on était trop impressionnés par ce genre de choses (qui illustre assez bien l'idée de la programmation réactive distillée jusqu'à son gros intestin):
C'est peut-être un peu raté mais j'essaye de vous faire subtilement comprendre que ces aspects réactifs ne sont pas natifs ni naturels en JavaScript.
Il va falloir tordre le langage pour y parvenir et il y a beaucoup de chances que ça implique des compromis, particulièrement en terme de coût en performances et en nombre de kilo-octets de JS à télécharger.
Pourquoi modéliser en composants?
Je dois vous avouer que j'ai mis un petit temps à comprendre l'intérêt de la généralisation du découpage en composants qui est utilisé par tous les frameworks et autres librairies JS.
Les tests
Comme je le disais plus haut, je n'ai pas écrit un seul test pendant mes études et je ne me souviens vraiment pas que le sujet ait été abordé d'une quelconque manière.
Je me souviens de la première fois que j'ai entendu parler d'injection de dépendance dans le contexte du Spring Framework (parce qu'à l'époque c'était l'âge d'or du Java (je suis vieux)), ma première impression c'était "pourquoi est-ce qu'on a absolument besoin d'un gros framework et 1000 dépendances Maven pour absolument avoir quelques annotations et facilités à utiliser de l'injection de dépendance"?
PARCE QUE LES TESTS.
C'est pas une vraie phrase mais c'est vrai quand même. J'ai fini par me rendre compte que la plupart des concepts qui me paraissent alien et/ou superflus dans la programmation moderne ont presque toujours le même dénominateur commun: PARCE QUE LES TESTS.
J'imagine que ma jeune audience est déjà bien renseignée sur le concept de test unitaire.
Ces tests sont supposés être rapides et atomiques.
Pouvoir tester des petits morceaux de code indépendants et assignés à une fonctionnalité bien définie, c'est plutôt pas mal.
Un peu comme écrire des tests unitaires pour une classe comme dans ces vieux langages périmés pour dinosaures tels que Java et C#.
Utiliser un découpage en composant d'interface se rapproche de cette idée en allant jusqu'à utliser une classe JavaScript pour représenter un composant.
Utiliser des composants augmente tout de même indéniablement la testabilité, ce qui est extrêmement favorisé en programmation moderne, peu importe le prix que ça occasionne en terme de complexité, de dépendances additionnelles, et parfois d'absurde (voir plus loin).
Le saucissonnage
Travailler à plusieurs c'est toujours rude.
On est biologiquement cablés pour coopérer avec les autres humains, chercher un sens de communauté et grandir ensembles.
Le problème c'est que les autres humains sont aussi super chiants et vont vous pondre d'affreux merge de leur branche qui devait juste corriger un bug mais ajoute aussi un tas de modifications en conflit avec la branche principale et vous devez passer 5h à vous battre avec Git pour intégrer tout ça à vos propres changements.
C'est encore pire si tout ce travail doit se faire dans un bureau avec les autres gens et leurs odeurs corporelles. Mais je m'égare.
Découper le projet en composants (de préférence beaucoup (trop) de composants) baisse le risque d'avoir des conflits lors du travail à plusieurs et rend plus clair quels aspects ont été modifiés au niveau d'une suite de commit ce qui permet à son tour d'identifier plus facilement la personne qui a ruiné tel ou tel truc pour ensuite l'humilier en public. En suivant le code de conduite, bien entendu.
Impose une structure commune
Encore un point important pour les humains qui travaillent en groupe, les frameworks par définition imposent une manière bien définie de travailler.
Certains sont plus ou moins souples sur certains aspects, mais des conventions sont toujours présentes.
Néanmoins, "utiliser des composants" ne passe pas nécessairement par un framework. Il est possible d'écrire des web components natifs (on le verra plus tard) un peu comme on veut.
C'est également possible d'imposer une structure dans un non-framework. Je pourrais vous le prouver, mais pourquoi je devrais vous le prouver?
Découplage avec l'interface
Les composants des frameworks JS embarquent du code de présentation (HTML/CSS) dans leur définition, parfois même l'intégralité de leur apparence.
Ceci viole un vieux principe appelé en anglais separation of concerns et qui souligne la bonne pratique d'essayer d'avoir du code modulaire qui soit totalement indépendant de la partie présentation.
Dans le développement web, on vomit constamment du caca sur ce principe.
La section en cours laisse entendre qu'il s'agit d'un avantage du découpage par composant mais ça génère plusieurs inconvénients:
- Les composants ne sont pas totalement indépendants. Les utiliser tels quels dans une application qui a une autre apparence ça va peut-être pas le faire, à moins d'avoir des styles globaux extrêmement bien pensés. Ils ont aussi tendance à venir avec leurs propres dépendances qui peuvent prendre la forme d'un énorme boulet métaphorifique;
- Comprendre exactement d'où vient un style particulier qui s'applique peut s'avérer encore plus compliqué qu'avant;
- Les composants doivent définir eux-mêmes (ou pas) les différentes propriétés d'accessibilités.
En revanche, on gagne la certitude que les composants sont montés sur une page web dans leur intégralité, avec leur apparence et leur comportement, en même temps.
Si un navigateur a le JavaScript désactivé, le composant n'est pas monté et donc ne s'affiche pas du tout. C'est mieux que d'afficher des bidules qui ne font rien.
Vous allez peut-être me dire que si rien n'est monté, l'application est de toutes façons inutile. Et vous avez raison sauf qu'il y a des moyens de rendre le tout plus progressif ou de proposer des fonctionnalités limitées en cas de JS désactivé (implique une génération côté serveur).
Imaginez une page d'article de blog générée par le serveur, l'article s'affiche que vous ayez le JS activé ou non. En bas de l'article, il y a un composant pour la liste de commentaires et un autre composant qui représente le formulaire de rédaction de commentaires. Si JS est désactivé, vous ne voyez simplement pas les commentaires et ne pouvez pas en ajouter, et ça c'est mieux que d'avoir tout le formulaire d'ajout de commentaire présent mais sans effet.
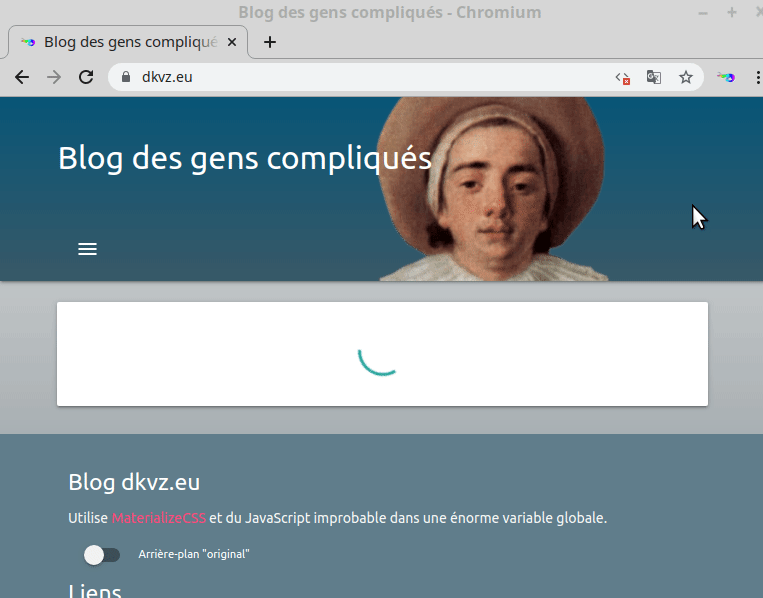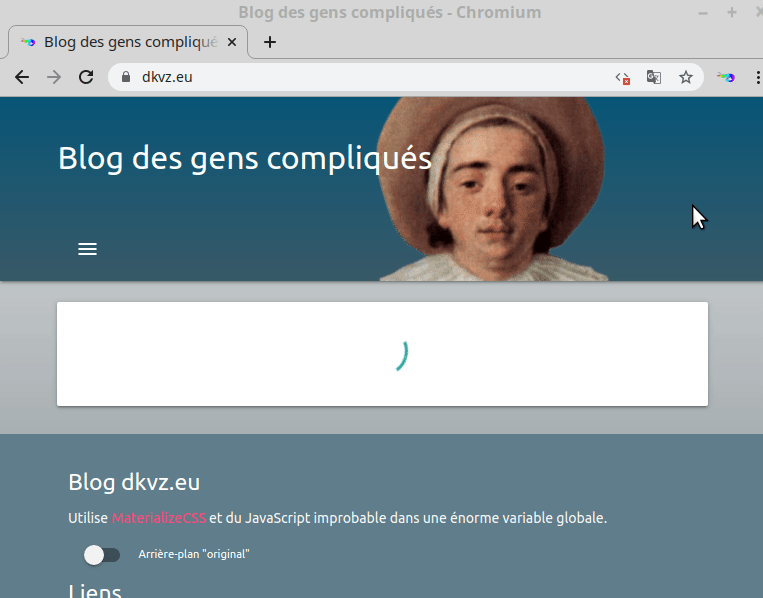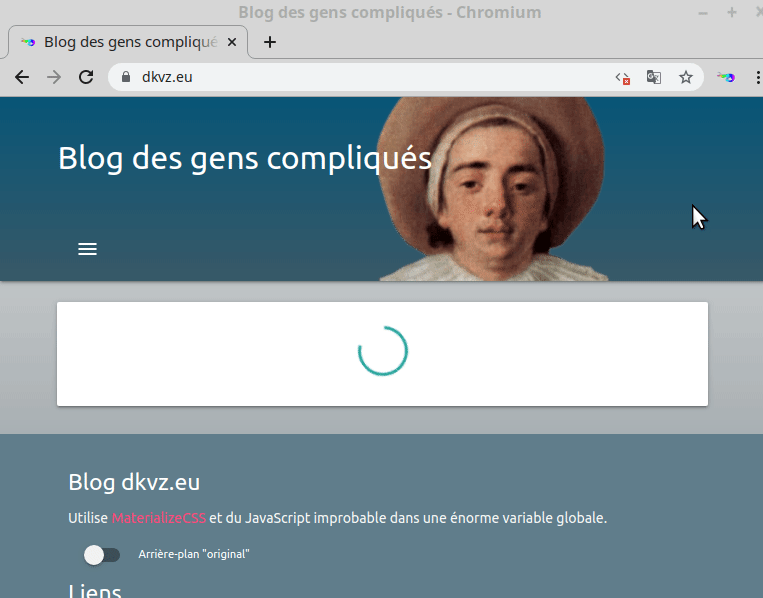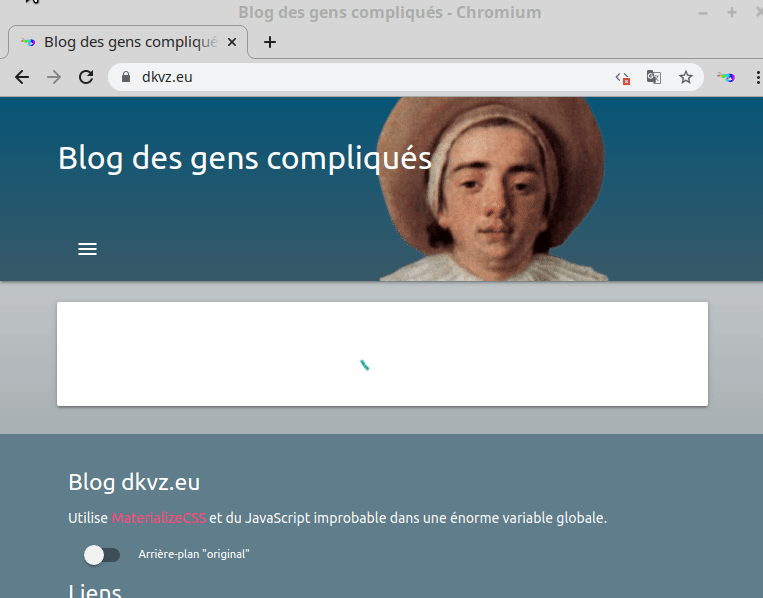
Quoi qu'il en soit, un bon prérequis pour une application moderne qui se respect est d'afficher au moins un message en cas de JS désactivé, ou en tous cas autre chose qu'un spinner qui tourne pour toujours comme sur ce site:
Conclusion
J'avais un à priori très négatif sur l'utilisation de composants qui est aujourd'hui presque entièrement dissipé puisqu'il est indéniable qu'ils sont difficiles à battre en terme de testabilité.
Pour une application qui n'a aucune utilité sans le JS activé, comme Capricartes, ça n'est pas très grave d'un peu nier les cas où le JS pourrait être désactivé.
De même si vous n'avez pas l'intention de faire de votre projet un sujet d'intégration continue open source, les tests c'est bien mais ce n'est potentiellement pas votre priorité.
Par contre, pour une application comme le présent blog, je dois avouer qu'il est possible de mieux faire.
En particulier ce serait beaucoup mieux d'avoir un hybride entre l'application simple page et une génération côté serveur.
Réfléchir en composants d'abord
J'ai écrit mes applications exemple sans réfléchir à un découpage particulier. J'ai dessiné la vue, puis j'ai ajouté du code qui fait des trucs.
Quand on utilise un framework JS, il s'agit de réfléchir au plus vite à comment découper l'affaire en composants.
Je vais vous expliquer pourquoi la généralisation absolue de cette pratique me fait un peu chier.
Je vous recase ma magnifique application exemple:
Il y plusieurs candidats composants dans tout ça. Je vais devoir faire des petits dessins.
Le cas d'école
Dans les bons vieux exemples de TODO APP les gens aiment bien découper en morceaux les plus petits possibles, un peu comme la notion de normalisation dans les bases de données relationnelles. Non? Okay je me suis encore emporté.
On pourrait utiliser ces composants (j'utilise des noms composés avec tirets en minuscule comme si j'allais utiliser des web components mais vous pouvez imaginer des noms comme GameLever si vous préférez):

C'est pas mega génial parce que game-status c'est juste une zone de texte qui fait rien d'autre qu'afficher un mono-truc, game-lever c'est juste un bouton, game-label c'est un autre truc qui affiche juste un machin, avec une étiquette devant...
Les seuls composants qui soient vraiment intéressants sont game-slots et game-slot.
Ils pourraient être utilisés pour facilement créer un jeu avec plus ou moins d'éléments slots où il y a réutilisation d'un composant relativement complexe et unique.
Je sais qu'en React c'est plus ou moins courant de créer un composant qui est juste un bouton... Mais... Non désolé je peux pas. Même en donnant tous les avantages précités au découpage en composant je ne peux pas aller jusqu'au bout de la réduction par l'absurde.
Réduction par fonctionnalité
J'ai pensé grouper tout ce qui contrôle le jeu dans un composant, et tout ce qui représente le jeu et l'affichage de son état dans un autre.
Ce qui donnerait ceci:

Je pense que je n'en ai pas encore parlé mais la plupart du temps, la manière dont les composants envoient de l'information vers l'extérieur revient à envoyer des évnénements. Parce qu'on est toujours dans une programmation événementielle n'est-ce pas.
Pour entrer des informations dans un composant, on peut également lui envoyer des événements, ou, modifier ses attributs/propriétés/[INSERER AUTRE TERME].
Avec ce type de découpage, il y a un composant qui contrôle clairement l'autre.
Le retournement de situation de FOU qui nous attend ici, c'est que c'est absolument impossible de modéliser une application par composant comme sur le schéma ci-dessus.
Bon, j'exagère un tout petit peu, c'est possible en utilisant une horreur de mise en page par positionnement absolu avec des tailles fixes et des calculs.
Le problème vient de la mise-en-page: disposer un composant indépendant qui possède tout son code de présentation en L c'est... Très difficile. Je vais même dire impossible à faire proprement, ça me semble pas mal.
Pour l'instant dans mon procédé j'ai perdu du temps à réduire à l'essentiel, pour me rendre compte que c'est absurde, essayer un truc plus générique, pour me rendre compte que je ne peux pas l'utiliser.
C'est bien parti. Surtout que je n'ai même pas parlé de l'histoire des affichages de la mise en cours et du total portefeuille qui sont aussi dans une autre zone de la mise-en-page mais que j'aurais voulu grouper avec le composant game.
Par fonctionnalité mais cette fois implémentable
Le modèle précédent étant totalement inutile, je pense qu'il va être nécessaire de découper le levier du reste, et grouper l'affichage de la mise et du total d'argent avec les contrôles, ce qui va demander de renommer ce composant pour refléter sa double personnalité.
Ca va être moche:

Non seulement un des composants cumule des rôles mais le levier ça reste juste un bouton. C'est un peu nul comme composant.
La réduction inverse
- Non mais là VEZDe, t'es un peu de mauvaise foi, si tu sais pas comment modéliser ce truc, utilise un seul composant.
C'est vrai. C'est une solution. Rien n'empêche d'utiliser un framework avec un seul composant.

On conserve les avantages d'utiliser des composants ou un framework, on oublie tout l'absurde et la perte de temps à essayer de trouver la meilleure modélisation.
Au pire on peut toujours tout refactorer plus tard, ce qui est de toutes façons l'histoire de la vie.
Je plaisante pas le sens de toute vie à base d'ADN c'est refactorer et faire des backups. Désolé de ruiner l'ambiance. J'en parlerai dans mon futur article sur la philosophie.
Reste que personnellement, si je modélise comme ça, je ne vais pas utiliser de framework. Ca n'a aucun sens pour moi.
La réduction raisonnable
Purée ils sont vraiment chouette mes titres.
En soi, la pièce centrale de mon application reste le groupe de trois images rotatives. Tout le reste sert soit à contrôler cette pièce, soit à afficher des données qui en viennent.
Par conséquent, pourquoi ne pas juste modéliser les composants que j'avais initialement imaginés: trois composants game-slot dans un composant game-slots.
Le tout communique avec des éléments extérieurs très simple par des événements et des propriétés/attributs:

Là, je suis un peu satisfait. Juste un gros double bémol: je suis maintenant obligé de coder une abstraction pour un élément rotatif de la machine à sous et pour bien faire de rendre le composant du niveau supérieur souple à la possibilité d'avoir un nombre arbitraire de ces éléments.
Je me suis donné potentiellement beaucoup plus de travail, juste parce que je voulais absolument avoir plusieurs composants.
JavaScript.
Cette version du modèle suppose soit que tout ne doit pas être un composant, soit qu'on a cette hiérarchie:
- Un composant racine, qui s'appelle App en général, ou "my-app" si on veut avoir un nom compatible web component, qui contient:
- Tous les éléments d'affichage du statut du jeu et tous les boutons de contrôle;
- Le composant qui contient les trois composants d'éléments rotatifs de la machine à sous.
Conclusion
En fait je sais pas trop où je voulais en venir avec toute cette section.
J'imagine que je voulais montrer mon chemin de pensée qui m'amène à conclure que découper en composants c'est parfois légèrement absurde et je pense que c'est mieux de ne pas trop en faire si possible et refactorer plus tard.
Il est également totalement inutile de se dire "hey je vais faire de ceci un composant parce que je pourrais en avoir besoin dans une autre app!" — personne ne réutilise des composants d'une application spécialisée à une autre. Enfin, c'est peut-être arrivé deux fois dans l'histoire mais je suis même pas sûr.
En fait, c'est possible de découper en composants sans utiliser de frameworks (et sans les web components).
Et ne venez pas me dire:
Celui qui n'utilise pas de framework en revient toujours à créer son propre framework.
Parce que même si c'est vaguement vrai, créer son propre framework en 15 lignes de JS c'est toujours une nette victoire sur n'importe quelle autre possibilité.
- "Oui mais gnagnagna c'est sûrement moins testable tu sais hein!"
Il est possible d'écrire du code tout à fait testable sans framework. C'est peut-être un tout petit peu plus de travail, mais c'est possible.
La gestion d'état
Modéliser en composants c'est pas mal mais c'est pas que du bonheur.
La problématique de la gestion d'état passe facilement de inexistante pour une TODO APP à extrême douleur au niveau du postérieur, et ce pour pratiquement n'importe quelle application un petit peu compliquée.
Chaque composant est libre de conserver son état interne, mais quid de l'état global? Par exemple, comment savoir si l'utilisateur courant est authentifié ou non?
Normalement, le composant racine (qui s'appelle souvent <App >) est en charge des informations sur l'utilisateur et donc de s'il est connecté ou non. Il passe cette information aux composants qui en ont besoin en tant qu'attribut, et les composants éventuels qui pourraient avoir un effet sur le statut de connexion de l'utilisateur, comme un bouton de déconnexion, remontent l'information jusqu'au composant racine via des événements.
Ce n'est pas le composant "bouton de déconnexion" qui réalise la déconnexion. Il ne fait qu'envoyer un événement qui trouve son chemin jusqu'au composant racine, qui récupère l'événement, et déconnecte l'utilisateur (puis repasse le statut de connexion à tous les composants enfants n'est-ce pas).
Enfin, ça, c'est le cas idéal de flux d'information entre composants: passage par props de haut en bas (si le composant racine est tout en haut) et passage par événements de bas en haut.
Concrètement ce cas idéal n'est pas du tout idéal du tout dans le genre vraiment pas parce qu'on en arrive assez vite à devoir passer 100000 d'informations indépendants par attributs à toutes sortes de composants avec des situations bien crades du genre:
Je n'avais pas prévu de passer le statut de connexion de l'utilisateur au composant Navbar mais depuis que j'ai mis un bouton de connexion/déconnexion dedans il me faut ce statut de connexion dans Navbar, pour ensuite ne rien faire avec et le passer au bouton.
Merci c'était bien clair.
On en arrive à passer de l'info par attribut/prop à un composant qui en fait le passe à un autre composant qui le passe à un autre composant qui le passe à un autre composant qui le passe à un autre composant qui l'utilise pour décider s'il affiche une icône verte ou orange foncée.
Moche.
Ce bon vieux composant racine doit gérer pratiquement TOUS les événements du monde, ce qui le gonfle potentiellement de dizaines et dizaines de fonctions.
Moche.
Les gestionnaires d'état
Des gens se sont dit qu'il suffirait d'envoyer certains événements à un organe indépendant qui n'est pas le composant racine, mais que les composants qui doivent modifier l'état global se partagent.
Cet "organe indépendant" pourrait être un bus d'événements. Moi ça me semble simple et élégant. Mais personne ne fait ça (à part parfois avec Vue mais il a son propre système de gestion d'état qui est bien plus populaire).
Non, les gens préfèrent utiliser des systèmes infernaux à base d'un "store" global qui gère à lui-seul toutes les variables d'état à partager entre différents composants (ainsi que parfois les méthodes qui permettent de modifier cet état).
Ce sont ces machins qui m'ont dégouté des frameworks JS et le pire c'est qu'ils sont plus ou moins obligatoires si votre application est un petit peu sérieuse.
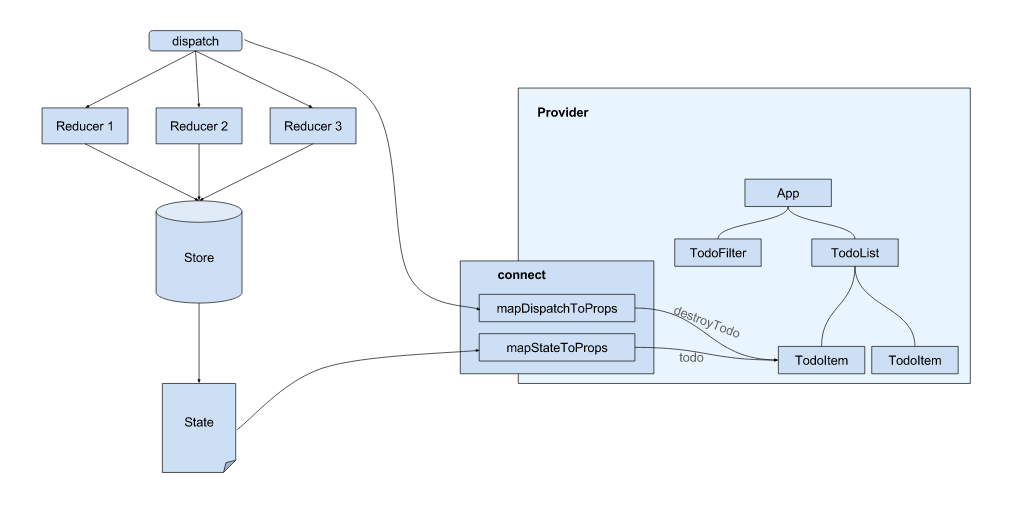
Le gestionnaire d'état le plus légendaire est Redux, qui vient du monde React.
Plutôt que vous montrer du code, je peux vous montrer ce schéma très sérieux d'implémentation de Redux pour une TODO APP que j'ai trouvé sur un vrai post Stackoverflow sérieux:
Récemment l'auteur de Redux lui-même était en train de clasher Redux sur Twitter:
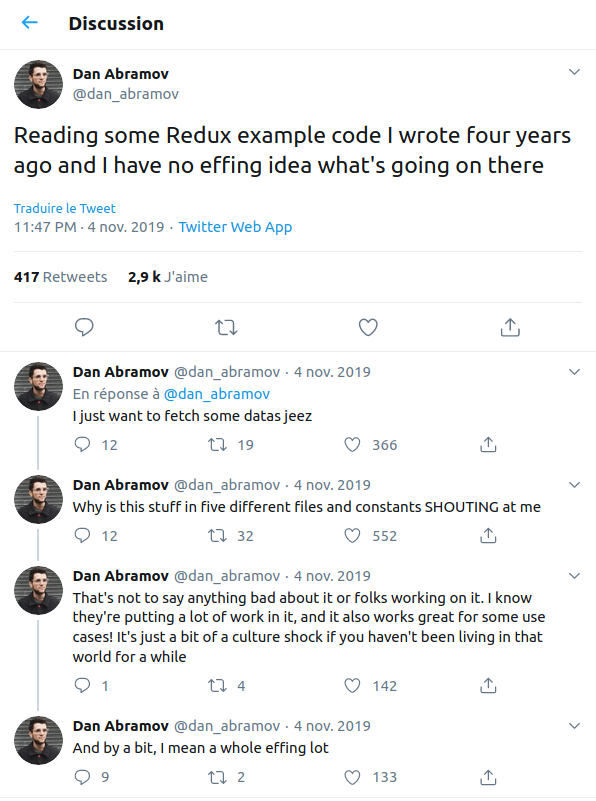
Fort heureusement la gestion d'état a évolué et il existe d'autres solutions que Redux. Vue a VuEX, Svelte a son propre système de store, React a des solutions alternatives à Redux dont une intégrée à la librairie (puis utiliser un BUS D'EVENEMENT est toujours possible si vous êtes un peu bizarre).
Toujours est-il que pour moi toute cette histoire de store global est un gros point noir des frameworks et j'ai décidé de ne plus trop en parler après cette section.
Les web components sont un peu mieux lottis parce que vous êtes extrêmement libres et pouvez par exemple passer une référence à un objet JS d'état à tous les composants qui en ont besoin, mais c'est pas génial non plus.
Pour bien faire, choisir un framework devrait passer obligatoirement par une revue des systèmes de gestions d'état qui lui sont intégrés. Et ça on vous le montre jamais dans les démos parce que c'est un peu compliqué, quoi.
Souvenez-vous juste de mon conseil: utilisez systématiquement un système de gestion d'état dès le début (à moins qu'il s'agisse d'une TODO APP ou une machine à sous).
Voilà maintenant j'en parle plus jamais parce que ça me pompe le nombril.
Revue des frameworks / librairies et possibilités natives
Il est temps. Examinons les différents acteurs majeurs en terme de frontend JS et s'ils peuvent m'aider à m'approcher de ce que je considère comme idéal en terme de développement web.
React
React est une librairie JavaScript développée par Facebook, ce qui pour certains est déjà un sérieux problème parce que Facebook est, au mieux, d'alignement chaotique neutre. Mais au mieux hein.
Fût un temps où la licence attachée à la librairie leur donnait un peu trop de droits, ce qui n'a pas aidé à réduire la crainte d'abus.
C'est une longue histoire, au final ils ont cédé et attaché une licence open source classique (MIT je pense, je dois avouer que je m'en fous un peu).
React peut avoir des abords complexes et étranges mais il est en fait très proche du JavaScript natif.
Que veux-je dire par là? La plupart des frameworks et apparentés JS ont une étape de compilation d'une manière ou d'une autre. C'est à dire que le code doit passer dans une moulinette avant d'être utilisable dans un navigateur.
Parfois, cette moulinette est absolument obligatoire (Svelte par ex.) et dans d'autre cas il y a moyen de totalement s'en passer.
React est bien plus proche de la seconde possibilité que de la première, même s'il est très rarement (je pense qu'on aurait le droit de dire "jamais") utilisé sans étape de compilation.
Il est d'ailleurs tellement proche du JS natif que j'ai un peu de mal à comprendre pourquoi la librairie pèse plus de 100Ko minifiée.
Surtout qu'il existe une librairie presqu'entièrement compatible et indépendante de Facebook qui s'appelle Preact et qui ne pèse qu'à peu près 16Ko minifiée.
Donc mon premier constat à propos de React c'est qu'il vaut probablement mieux ne pas utiliser React, mais utiliser Preact. Vous suivez?
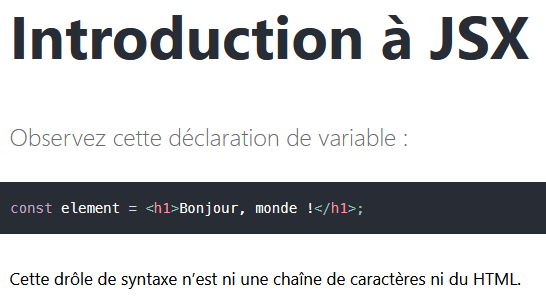
L'élément principal à motiver une étape de compilation pour React est le pseudo langage qu'il utilise pour représenter la partie présentation: le JSX.
Il s'agit en gros d'HTML avec du JavaScript dedans, qui est compilé en JavaScript pur par un plugin Babel.
Si vous voulez un petit exemple sympa qui illustre à quel point le JSX est proche du JS, on n'utilise pas l'attribut class pour assigner des classes CSS à un élément, mais className, qui est l'attribut tel qu'on l'utiliserait en JS et pas en HTML.
<!-- Ceci ne fonctionne pas en HTML -->
<span class-name="truc">Coucou</span>// Ceci fonctionne en JS
document.querySelector('span').className = 'truc';Ce qui veut dire que le JSX ressemble à du HTML, mais... C'est pas du HTML. Ouais. C'est génial quoi merci React.
Rendons ça réactif!
Pour obtenir l'aspect réactif que je vous ai présenté quelque part plus haut et qui est directement dans le nom de la librairie tout en restant proche du langage et en limitant les compilations nécessaires, React utilise un artifice infâme appelé Virtual DOM en essayant vaguement de vous vendre que c'est une idée de génie et que c'est très rapide.
C'est une assez belle pièce d'ingénierie, je l'accorde. Par contre, c'est vraiment pas rapide.
Le Virtual DOM
Si vous avez lu les 3000km de texte qui précèdent, vous vous souvenez peut-être qu'il y a un style de programmation en grande demande: le déclaratif [événementiel && fonctionnel] et réactif.
C'est-à-dire que l'on s'attend à ce que modifier une variable d'état (qui s'appelle d'ailleurs state dans le monde React) entraîne une mise-à-jour automatique de l'affichage.
Pour remplir cette obligation, React maintient une liste interne de l'arborescence de composants et de tous les éléments HTML et autres composants qui les composent (burps), le tout indépendamment du véritable DOM affiché par le navigateur.
Cette arborescence part toujours d'un et d'un seul composant racine (qui s'appelle générallement <App />, je crois que je l'ai déjà dit quelques fois).
Une règle est imposée à, que je sache, tous les frameworks qui utilisent un Virtual DOM et aussi certains qui n'en utilisent pas: le corps de chaque composant doit être constitué d'un et un seul élément racine même si ça n'a aucun sens par rapport à ce que vous voulez faire.
Avant ça signifiais AJOUTER PLEIN DE DIV, aujourd'hui il existe un noeud spécial React appelé <React.Fragment> qui peut servir d'élément racine quand votre composant n'en a pas qui soit évident.

Chaque composant React est un objet JS qui possède une méthode nommée render() qui génère la parte de Virtual DOM qui lui correspond.
Alors, oui, les composants dits "fonctionnels" n'ont pas de méthode render(), ils ont comme valeur de retour ce que renverrait la méthode render() d'une classe équivalente. Merci React de bien compliquer mon article qui n'était pas assez long.
Si le Virtual DOM contient d'autres composants React, leurs méthodes render() sont également appelées, et ainsi de suite en descendant l'arborescence.
Pour ma super application exemple, la méthode render() pour renvoyer ceci (ou bien ce serait la valeur de retour de la fonction App s'il s'agit d'un composant fonctionnel):
return (
<div>
<h1>Le titre du truc</h1>
<div>
<div>{status}</div>
<GameSlots />
<button onClick={() => runGame()}>LEVIER</button>
<hr />
<button onClick={() => resetGame()}>Réinitialiser</button>
<button onClick={() => setBet(bet + 5)}>Mise+</button>
<button onClick={() => setBet(bet - 5)}>Mise-</button>
</div>
</div>
);Où:
- Tout est très simplifié au niveau disposition;
- J'utilise la modélisation réalisée plus haut;
- La variable status vaut "Gagné!" ou "Perdu!";
- On imagine qu'il y a une fonction runGame quelque part qui lance le jeu;
- Mis à part <GameSlots> qui est un composant React, tous les éléments de ce Virtual DOM sont des éléments HTML natifs;
- Le composant <GameSlots> a besoin de tout un tas de props pour communiquer l'état du jeu, à moins d'utiliser un système de state management ou équivalent — Je propose de laisser ça de côté pour le moment.
Modifier une variable d'état d'un composant doit obligatoirement passer par une méthode spécifique à React (par exemple dans le code plus haut, setBet() serait une de ces fonctions spéciales), qui va déclencher une mise-à-jour complète du Virtual DOM à partir du composant où l'état a été modifié — c'est-à-dire que toutes les méthodes render() des composants présents dans l'arborescence qui nous concerne vont être appelées.
La doc de React va essayer de vous vendre un sac en disant que cette opération est "légère".
Je dirai juste que tout est relatif... Surtout que c'est pas terminé parce qu'on a encore rien affiché sur l'écran de l'utilisateur final.
Il s'agit maintenant de comparer le nouveau Virtual DOM avec une copie de l'ancien.
Ce procédé est appelé diffing et permet d'isoler les noeuds qu'il faudra effectivement ajouter, retirer ou modifier dans le véritable DOM.
Une fois que la liste de ces opérations est prête, il suffit de les exécuter, et le résultat s'affiche.
Je tiens à rappeler que toute cette affaire se produit à chaque modification de variable d'était, à moins d'avoir tripoté certaines méthodes de cycle de vie pour empêcher la mise-à-jour dans certaines conditions, mais ce n'est même pas certain qu'ajouter ce genre de mises-à-jour conditionnelles augmente réellement les performances.
Pire encore, normalement l'état de votre application est centralisé dans le composant racine, et tous les composants enfants modifient cet état via des événements qui sont rapportés au composant racine (à moins d'utiliser une GESTIONNAIRE D'ETAT mais cet article sent déjà trop le vomi pour parler de ça maintenant).
Ceci signifie que toute modification d'état appelle toutes les méthodes render() de tous les composants de l'application. Non, je plaisante pas.
C'est de cette manière que l'aspect réactif est obtenu.
Un exemple SVP
Etant donné que je suis un genre d'expert en barres de progression, je vais utiliser ça comme exemple simple-mais-non-moins-inutile pour démontrer l'aspect réactif et à quel point c'est simple à écrire avec React (en pratique c'était pas aussi simple que ça aurait dû mais laissons ça de côté pour l'instant).
Nous allons avoir besoin d'une variable d'état qui représente la progression d'une opération de 0 à 100 dans le composant racine, ainsi que d'un composant ProgressBar qui reçoit cette variable d'état et affiche la progression.
Code du composant racine:
import React, { useState } from 'react';
import './App.css';
import ProgressBar from './ProgressBar';
import ProgressMaker from './ProgressMaker';
function App() {
// Récupère une variable d'état "progress"
// Et une fonction pour la modifier.
// Initialise la valeur à 0.
const [progress, setProgress] = useState(0);
// Ajouter de la progression factice:
ProgressMaker.start(setProgress);
return (
<div>
<h1>Ma super application illustrative</h1>
<ProgressBar progress={progress} />
</div>
);
}
export default App;Ne faites pas attention à ProgressMaker pour l'instant. Nous utilisons ici les React Hooks plutôt qu'une classe pour décrire le composant. Je trouve ça beaucoup moins clair perso mais ils ont tout un tas de raisons comme quoi c'est mieux puis tout le monde utilise ça maintenant alors je me suis dit pourquoi que je m'y mettrais pas.
Le composant ProgressBar est encore plus simple:
import React from 'react';
function ProgressBar(props) {
const baseStyle = {
backgroundColor: '#edebed',
height: '32px',
boxShadow: '2px 2px 6px #fff',
width: '0%'
};
props.progress &&
(baseStyle.width = props.progress + '%');
return (
<div style={baseStyle}></div>
);
}
export default ProgressBar;Ce composant n'a pas besoin de variables d'état, il est stateless comme on dit [pas]chez nous. Il reçoit par ailleurs la progression dans ses "props" et n'a pas vraiment de code de logique, il ne fait qu'afficher ce qu'il reçoit et c'est tout.
Pour dessiner la progress bar j'utilise des CSS en ligne qui sont écrits en JavaScript. Vous avez le droit de trouver ça moche.
Résultat (120Ko de JS lel):
Facile hein. Sauf que j'ai du écrire tout un genre de hack caché derrière ce fameux ProgressMaker.
Moi je voulais juste ajouter ça dans le composant App:
const interval = setInterval(
() => {
setProgress(progress + 5);
(progress >= 100) && clearInterval(interval);
},
300
);Sauf qu'on peut pas. A cause des HOOKS.
Dans un composant classe on pourrait tranquilement lancer ça depuis le constructeur. Avec les hooks setInterval combiné à une modification d'état provoque un rerender du composant App, qui relance le setInterval depuis 0, qui rerender, et ainsi de suite.
Le très sympatique Dan Abramov explique pourquoi ça marche pas dans un post de blog où il propose toute une solution infernale que je n'ai pas lue.
A y réfléchir, le setInterval qui augmente artificiellement la progression devrait être dans une méthode de cycle de vie de React (qu'il faudrait ramener avec un infâme useEffect ou truc du genre qui aurait de toutes façons été moche) et pas dans le corps de la fonction de rendu (un composant fonctionnel c'est juste une fonction de rendu) — vous pouvez dire que c'est de ma faute d'avoir voulu faire UN PEU TROP SIMPLE.
Finalement j'ai juste tiré parti de ce bon vieux Webpack (intégré automatiquement (que je sache) aux applications créées avec le script create-react-app) et comment il importe les modules et j'ai créé un fichier ProgressMaker.js qui contient juste ceci:
export default {
running: false,
start: function(setProgress) {
if (!this.running) {
this.running = true;
let progress = 0;
const interval = setInterval(
() => {
progress += 5;
setProgress(progress);
(progress >= 100) && clearInterval(interval);
},
300
);
}
}
};Et puis voilà, ça marche.
Les frameworks JS c'est parfois un peu comme avec Linux, on se lance dans un truc simple genre l'installation d'un driver graphique et deux heures plus tard on est en train de recompiler des modules étranges avec un niveau d'espoir en baisse.
Mon avis
Fût un temps où j'étais vraiment pas fan de React du tout. Je me suis assagi considérablement depuis et lui trouve juste deux boutons blancs qui font mal:
- Il utilise un Virtual DOM = LENT;
- Il fait plus de 50Ko compressé et minifié.
Le deuxième point disparaît si on choisir d'utiliser Preact, ce que je conseille. Certaines choses ne seront peut-être pas compatibles, auquel cas mon conseil est de ne pas utiliser ces certaines choses. Merci moi.
L'écosystème React est vaste. Difficile de ne pas citer des projets comme Gatsby, un puissant générateur de sites statiques (ou moins statiques si on veut) ou encore NextJS, les deux ouvrant la possibilité d'avoir une génération côté serveur en tandem avec la navigation JS qui donne les interfaces les plus réactives.
Le projet React Native permet de créer des applications Android et IOS en utilisant JS et React (autant vous dire que c'est légèrement épais et lent).
Citons également create-react-app, un script node qui permet de facilement créer des applications simple-page React (dont le répertoire pèse déjà initialement 210Mo avec toutes ses dépendances, faut bien ça, hein).
Comme React s'occupe de la partie présentation/vue uniquement, vous avez champ libre pour énormément de décisions de librairies à utiliser ou de méthodes de développement à suivre (TypeScript ou pas? Conventions de nommages et de placement de fichiers? Etc.).
Etant proche du JS natif, il est relativement simple et en tout cas peu contraignant d'intégrer [P]React à n'importe quel projet existant si vous savez ce que vous faites.
Comme expliqué plus haut, être proche du JS natif implique certains inconvénients. Par exemple la manière dont j'ai intégré le CSS dans mon composant ProgressBar plus haut, les propriétés des éléments HTML du JSX qui doivent être leurs versions JavaScript (className au lieu de class, onClick au lieu de onclick, ...).
On se sent un peu sale au début mais après ça passe.
Je l'ai même tweeté un jour:
Vue
Vue vend la même chose que React: un moyen de créer des interfaces déclaratives et réactives en JS.
Si on plisse fort les yeux, on pourrait dire qu'il y a deux manières d'utiliser Vue: une approche similaire à React, proche du JS natif, qui a besoin de peu voire pas de compilation du tout, et une approche qui utilise un nouveau type de fichier pour représenter un composant Vue, avec l'extension .vue.
Autant vous le dire tout de suite, personne n'utilise la première approche. J'arrête tout de suite d'en parler mais comme ça vous êtes au courant que c'est possible.
Il va de soi que pour utiliser ces fichiers .vue il faudra passer par une étape de compilation obligatoire (qui utilise Webpack, que je sache).
Un composant Vue est donc générallement un fichier unique bien propre avec trois sections séparées (qui peuvent être chargées depuis d'autres fichiers, si vous le voulez vraiment):
- Le code JavaScript (ou TypeScript) du composant avec une structure déterminée pour stocker les variables d'état, méthodes de cycle de vie, etc. Comme Webpack traine derrière, tous les imports de toutes sortes de types de contenu avec leurs loader et toute cette belle magie (**bruit de prout**) sont possibles;
- Les CSS, avec support de SCSS;
- La présentation (HTML) avec support de langages de templating, et cette fois-ci les vrais attributs HTML (class et pas className).
Le tout joliment emballé dans des tags <script>, <style> et <template> respectivement.
Fun fact totalement inutile: cette structure copie exactement les premières versions de Polymer, qui est une librairie construire au dessus des web components natifs et dont on parlera plus tard.
Vue ajoute des attributs uniques pour gérer tous les bindings avec le modèle et, comme la partie script suit également une structure précise, l'aspect MVVM (discuté plus haut) est bien plus évident ici qu'avec React.
React permet d'insérer simplement du JavaScript entre {} en plein milieu du JSX. Et ça marche. Parce que JSX est une vague mince couche au dessus du JavaScript.
Le template Vue est à un autre niveau d'abstraction et j'espère que ce sera clair quand on passera aux exemples.
Le Virtual DOM
Vue utilise pour l'instant un Virtual DOM pour obtenir l'aspect "réactif" tant désiré.
Je ne vais pas tout réexpliquer, le concept est le même que pour React.
La lenteur encourue est aussi la même. Bien qu'ils prétendent être plus rapides que React, pour ce que ça vaut.
Un exemple SVP
Reprenons l'histoire de la barre de progression afin de faciliter la comparaison avec React.
Le code du composant racine App est un peu plus long, mais je trouve qu'il est aussi beaucoup plus clair.
<template>
<div>
<h1>Ma super application illustrative</h1>
<ProgressBar :progress="progress" />
</div>
</template>
<script>
import ProgressBar from './components/ProgressBar';
export default {
name: 'app',
components: {
ProgressBar
},
data: function() {
return {
progress: 0
};
},
mounted: function() {
const interval = setInterval(
() => {
this.progress += 5;
(this.progress >= 100) && clearInterval(interval);
},
300
);
}
}
</script>
<style>
</style>Où:
- Il s'agit d'importer et enregistrer les compostants qui vont être utilisés, avec un import classique suivi d'un ajout dans la section components du script du composant Vue. Je n'ai aucune idée de pourquoi cette redondance est nécessaire;
- Les variables d'état sont dans un objet renvoyé par une fonction qui s'appelle data. Si vous trouvez que cette phrase est fort compliquée c'est parce qu'elle l'est. Ces variables sont disponibles immédiatement dans le mot clé "this" pour toutes les méthodes du composant (y compris celle du cycle de vie) — ce que je trouve bien chouette;
- Cette fois-ci on déclare la progression artificielle dans une méthode de cycle de vie qui s'appelle mounted, du coup plus de problème étrange de boucle de rendu comme pour mon exemple React;
- Le template mentionne l'attribut ":progress" sur le composant ProgressBar, c'est un raccourci pour v-bind:progress et nous permet de créer un binding avec une variable d'état mentionnée directement par son nom;
- Le binding d'événement (y en a pas dans cet exemple, je précise) utilise le caractère "@", comme ça c'est bien clair quand un argument est une fonction (c'est pas nécessairement clair avec React);
- Cette liste à puces est beaucoup trop longue.
Le composant ProgressBar ne possède pas de variables d'état, juste une propriété "progress":
<template>
<div class="progress"
:style="{ width: progress + '%' }"
>
</div>
</template>
<script>
export default {
name: 'ProgressBar',
props: {
progress: Number
}
}
</script>
<style scoped>
.progress {
background-color: #edebed;
height: 32px;
box-shadow: 2px 2px 6px #fff;
}
</style>ATTENTION nouveau largage de de liste à puces:
- Le type de la propriété est mentionné — C'est une pratique courante pour les composants Vue;
- Le style de base de la barre de progression est bien au chaud dans son élément style qui possède un attribut spécial demandant de s'assurer que ces styles ne seront pas ajoutés aux styles globaux mais n'existeront que dans le contexte de ce composant, ce qui est tout de même très utile;
- La progression est liée à l'attribut "style" en utilisant un objet et une courte expression JavaScript, parce que oui, c'est autorisé.
Observez le résultat pour un coût d'un peu moins de 100Ko de JS:
Mon avis
Vous constaterez en observant les exemples que Vue utilise un style déclaratif et réactif, comme React, sauf que je trouve que le déclaratif de Vue est beaucoup plus déclaratif.
Ma préférence pend déjà du côté de Vue rien que pour ça. En règle générale, la séparation bien claire entre les parties présentation et comportement et la structure bien définie de la partie script ont beaucoup de sens pour moi.
Comme pour React vous restez libre pour ce qui est de nombreux choix psychologiques techniques en terme de librairies, structure du projet, méthodologie, utilisation de TypeScript etc.
Vue dispose de sa propre engeance de React Native, qui s'appelle... Vue Native je pense.
En règle général ils ont des équivalence pour tous les acteurs proéminents de la scène React et un système de gestion d'état qui est bien plus clair que l'horreur qu'est Redux, qui est tellement horrible que j'ai évité à tout prix d'en parler alors que ça a l'air particulièrement compliqué de me retenir d'écrire 15 pages sur une modélisation en composants.
Je n'en dirai pas plus.
En résumé, j'aime bien Vue. Sauf que la librairie ajoute plus de 50Ko de JS et utilise un Virtual DOM donc... J'aime juste un peu plus de React, quoi.
Angular
Sauf défaut de compréhension lexical majeur de ma part, Angular est le seul véritable FRAMEWORK présenté ici si l'on exclut la terminologie UI framework. Baaaah je sais pas pourquoi je m'attarde tellement sur la terminologie, j'ai un problème docteur (sans blague).
Les VRAIS FRAMEWORKS sont plus difficiles à tordre pour essayer de faire des choses ANTI-PATRONS puisqu'ils vous imposent une manière de travailler bien particulière, suivent les traditions de cacher les détails d'implémentation et d'augmenter le niveau d'abstraction dès que possible. Ah oui, et vous êtes obligés d'utiliser TypeScript aussi. Alors, heureux?
Blague à part, pour certaines personnes, l'intégration directe avec TypeScript est une raison suffisante pour utiliser Angular plutôt que quoi que ce soit d'autre.
Je ne suis pas une de ces personnes. En tous cas pas encore;
J'écris de petits projets tout seul et je comprends aujourd'hui suffisamment JS (enfin je pense) pour ne pas avoir besoin des conseils du compilateur TypeScript. Qui sont, je souligne, intéressants quand on débute.
Les séparations en services, contrôleurs, etc. me font juste perdre du temps.
Il n'empêche que je peux comprendre l'intérêt pour le travail en équipe et l'intégration de personnes qui viennent d'autres langage, puisque la philosophie d'abstraction autour d'Angular ressemble très fort aux langages "sérieux" (pas le JS, quoi) et leurs frameworks.
Devoir écrire des interfaces TypeScript aide à auto-documenter le code, ce qui renforce encore plus la facilité de travailler en équipe.
Tout est bien lisse et pratiquement tout est prévu, y compris les tests unitaires (bien entendu) mais aussi ceux d'intégration, le code pour réaliser des requètes HTTP, ...
Le soucis majeur que j'ai avec Angular n'est pas lié au framework en lui-même mais plutôt au volume de JS qu'on doit se taper.
Avec RxJS, on approche dangereusement du Mo de JS.
Je vous aurais bien dit, bonne nouvelle, Angular n'utilise pas de Virtual DOM mais ça ne l'aide que très relativement parce qu'il est tellement gras qu'il est de toutes façons lent.
Je rappelle que ma préférence personnelle va à moins de 50Ko de JS non-compressé ajouté par les dépendances externes. Référence foireuse: le présent article pèse environ 160Ko de texte, et il est immense on est bien d'accord (d'autant plus que la source a des caractères en plus). Je vous laisse imaginer ce que représente Angular.
Si vous voulez vraiment un point positif performance: Une fois qu'il est chargé (important), Angular n'est pas plus lent que les autres. A vrai dire je me demande s'il n'est pas plus rapide mais faudrait tester.
Le framework est indéniablement très puissant et modulaire, populaire sur le marché du travail et même sur Twitch pour les live de dev frontend.
Sa rigidité est certainement un atout pour un gros projet, particulièrement si le backend est également écrit en JavaScript/TypeScript.
Même Google s'est mis à l'utiliser, plus ou moins. Parce que oui, c'est un projet Google au départ, qu'ils se sont bien tenus de ne surtout pas utiliser dans leurs produits (rassurant hein), jusqu'à relativement récemment où ils prétendent avoir refait Google Analytics en utilisant Angular/Dart qui est une mixture... Particulière. Passons.
Le truc c'est que là on est sur mon blog, et j'ai beau chercher je n'ai aucun usage personnel pour Angular. Il est juste trop gros et lent et inflexible par nature. Désolé.
A noter qu'il existe encore la toute première version d'Angular générallement désignée comme AngularJS ou parfois Angular 1. Ce framework là est obsolet depuis... Ben depuis qu'il a été créé je pense. Je parle de la version d'Angular qui suivra et qui est parfois désignée comme Angular 2 (alors qu'on est à la version 8 mais bon).
Les Web Components
Il ne faut pas être grand droïde pour remarquer une tendance: tout le monde veut définir et utiliser des composants, pseudo-indépendants, hypothétiquement réutilisables et surtout testables de manière atomique.
Des gens (dont la majorité semble venir de chez Google) décideront ultimement que ce serait pas mal d'avoir un standard natif pour définir et enregistrer de nouveaux éléments pour utilisation directe dans le DOM.
Vu le temps que ça a pris pour avoir un support des web components dans tout ce qui n'est pas Chrome (il y a dans les 200Ko de polyfill pour ceux qui veulent vraiment), je pense que les gens de Google ont un peu décidé tout seuls de ces standards. En tous cas ça en a l'air.
Surtout que cette histoire de web component (parfois repris comme Custom Component ou encore WC (lol c'est drôle, c'est comme Wok City)) a surgi quelque temps après que Google ait engagé tout un tas de développeurs web pour... Faire des trucs liés à Chrome.
Plaçons les dans une pièce quelque part à San Francisco qui coûte probablement une dizaine de reins par mois en loyer, payons les très cher, et ils devraient nous créer des "produits" qu'on euthanasiera plus tard.
Les étranges Service Workers (et les web workers en général) ont été excrétés par les mêmes gens autour de la même époque.
Le standard web components en lui-même est assez simple bien qu'il soit générallement associé à un autre concept (qui provient aussi du même endroit): le SHADOW DOM.
Ceci dit, nous n'en avons pas besoin pour écrire un web component simple:
class SuperElement extends HTMLElement {
constructor() {
super();
this.innerHTML = '<h1>Super Element</h1>';
}
}
customElements.define('super-element', SuperElement);J'ai utilisé une classe parce que c'est vraiment le plus clair pour définir des web components. Ils "héritent" de HTMLElement, ou éventuellement d'un composant plus spécialisé avec la finalité d'étendre son comportement - Par ex. si vous voulez un lien qui affiche en plus un tooltip euh... Ouais, n'entrons pas dans ce cas d'utilisation parce que cette section est déjà gigantesque.
Le constructeur est obligatoire juste pour au moins appeler la méthode super(). Ensuite dans ce cas particulier simple j'ai ajouté un élément h1 avec le texte "Super Element" dans le corps du composant.
Le mot clé "this" représente le composant courant au sein de la class, vous pouvez dès lors accomplir ces quelques menues tâches pratiques:
// Récupérer des éléments au sein du composant:
this.querySelector('.truc');
// Ajouter des fonctions à des événements
// Vous pouvez créer vos propres types d'événements
this.addEventListener('lechouille', this.handler);
// Ajouter des noeuds
this.appendChild(unElement);
// Et d'autres trucs...Les web components ont leur propres méthodes de cycle de vie.
Si une ligne telle que:
customElements.define('super-element', SuperElement);Est présente, il est alors possible d'utiliser l'élément directement dans le DOM:
<super-element></super-element>Contrairement aux composants React, Vue etc. qui sont traduits en noeuds DOM standard par JS, les web components apparaissent tels quels dans le DOM tel que vu par l'inspecteur du navigateur:
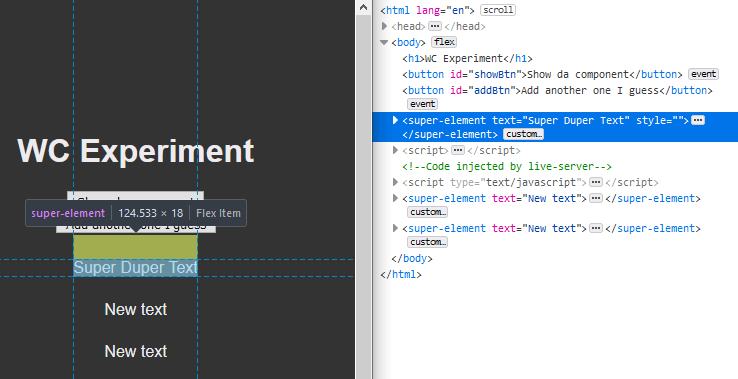
Si j'inspecte mon exemple React avec son composant ProgressBar, il n'y a en a plus aucune trace dans le DOM, c'est devenu un div avec des styles en ligne:
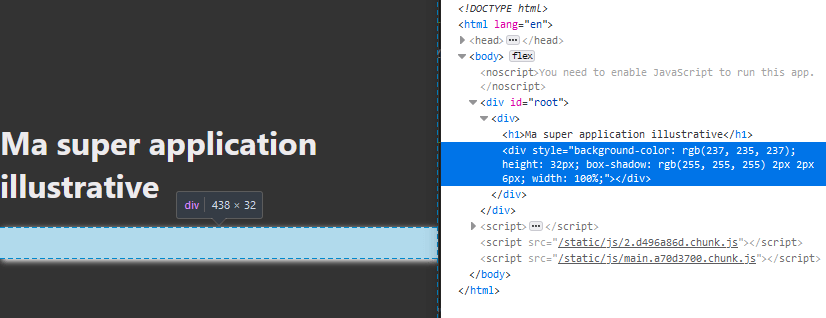
Je vous dis ça comme si c'était une surprise mais en fait les navigateurs intègrent naturellement au DOM tous les éléments, qu'ils existent en tant qu'éléments HTML standards ou non, ils sont simplement considérés comme un élément block standard (un div, quoi).
C'est important à mentionner parce que si JS est désactivé, le contenu du Custom Element va tout de même s'afficher. Ce qui peut être bien, ou pas bien.
Il n'y a aucun soucis à ajouter les éléments au DOM dans le script, comme React ou Vue le ferait en montant un élément racine quelque part.
C'est un thème récurrent avec les Web Components: PRATIQUEMENT TOUT EST PERMIS — la souplesse est maximale mais du coup ça devient aussi vite le bordel et on est parfois obligés d'écrire beaucoup de choses redondantes qui sont habituellement prises en charge par un Framework. Je vous illustrerai tout ça plus loin.
A noter qu'il est obligatoire d'utiliser un tiret et uniquement des lettres minuscules dans le nom de tous les web components ou vous aurez une grosse erreur quand la ligne customElements.define est atteinte. C'est pas moi qui ai décidé.
Support par les navigateurs
C'était au départ le gros point de contention pour les web components et reste un point majeur de la discussion puisqu'un de gros avantages d'utiliser ce standard est de ne pas avoir besoin de librairies et autres dépendances pour écrire et exécuter des web components.
Il existe un polyfill assez balaise, mais comme je le disais plus haut, il pèse plus de 200Ko (c'est toujours moins qu'Angular ceci dit). Il paraît qu'il ne charge dynamiquement que ce qui est nécessaire. Mais j'y crois qu'à 75%.
En résumé, ça ne fonctionne pas nativement sur IE, Edge avant qu'ils soient basés sur Chromium (JE REMERCIE ENCORE PETIT JESUS POUR CETTE DECISION), et Opera Mini (lol):
Le support du Shadow DOM est similaire.
Je ne peux même plus sortir mon argument de non-support par le robot Google puisqu'ils l'ont finalement mis-à-jour.
Un petit exemple
On va se refaire cette bonne vieille barre de progression. Au plus je réitère cet exemple au plus je me rends compte à quel point il est bien nul mais c'est trop tard maintenant.
Pour mes autres exemples j'avais utilisé create-react-app ou autres vue CLI pour créer un dossier de travail de 200Mo complet avec les tests, lintage, scripts de déploiement etc.
Ici on va bien mettre en emphase le côté natif des web components en écrivant juste une vieille page HTML tout seule sans rien d'autre. Taille du JS ajouté par les dépendances: 0.
Je vous invite à regarder le Gist si vous voulez voir toute la page, je vais détailler ce qui me semble important.
Le BODY
Dans <body> je suis parti sur l'idée particulièrement simple de juste avoir un "composant" racine dedans, comme quand j'utilisais le composant App pour React et Vue, sauf que... Ben on peut pas l'appeler App.
Je l'ai appelé my-app. C'est courant de voir des my-truc dans le "monde" assez restraint des web components. Vous allez voir de la sacrée belle magie aujourd'hui les enfants.
J'ai décidé d'ajouter du texte dans le tag qui fonctionne un peu comme un noscript mais plus spécialisé puisque ce texte s'affichera également dans le cas où JS est activé mais les web components ne sont pas supportés (IE11 par ex.):
<my-app>
Cette application ne fonctionne pas sans JavaScript
</my-app>Ce n'est pas une généralité des web components que de mettre du contenu de fallback dedans, oh non, c'est même probablement ANTI-PATRONS.
Dans mon cas précis ça fonctionne très bien parce que je retire le contenu du composant lors de sa déclaration pour le remplacer par mon modèle. Mais rien ne vous oblige à faire ça. Rien ne vous oblige à faire quoi que ce soit, c'est la jungle Okay?
Je tenais juste à souligner qu'il est tout à fait possible d'utiliser les web components de manière progressive (càd d'avoir un comportement décent si JS est désactivé) sans même être obligés de les monter via le JS comme on le ferait pour Vue ou React.
Il est d'ailleurs possible de styler l'élément, qu'il ait été enregistré ou pas, avec ou sans JS et au moins depuis IE11 (ça ne fonctionne pas sur IE6) — Vous ajoutez simplement un sélecteur tag dans vos styles globaux et affectez des CSS dans le but d'avoir un comportement limité mais visuellement sensible du web component.
Il existe même un obscur sélecteur :defined qui peut être utilisé avec ou sans :not() pour contrôler de plus près les styles de vos web components, sur des plateformes qui les supportent, avant ou après qu'ils soient activés au niveau JavaScript.
Bon par contre, et ce sera un des thèmes récurrent, vous devez tout faire vous-mêmes.
J'aurais pu dynamiquement créer le composant my-app et l'ajouter au body dans le script afin d'être certain que le composant soit bien totalement chargé avant de l'ajouter au DOM:
// Déclaration des composants etc.
// ...
document.body.appendChild(
document.createElement('my-app')
);Ce qui risque d'être un autre thème récurrent: j'aurais pu faire tout plein de trucs, le champ de possibilité englobe toute la plateforme, c'est-à-dire que document est de retour et qu'on tripote directement le DOM.
Déclarer les composants
J'utilise un tag script à la fin de <body>, comme d'habitude. Ce qui signifie qu'il peut y avoir un flash de style puisque les composants sont enregistrés dans le DOM avant qu'ils ne soient enregistrés comme web components.
Normalement il faudrait prévoir le coup et avoir un genre d'écran de chargement, ou bien simplement avoir déjà un style consistant pour les composants, que le JS soit exécuté ou non, par ex. en utilisant un sélecteur du genre my-app:not(:defined)).
Pour déclarer un web component, le plus simple est d'utiliser les classes JS. Je me rends compte qu'on a pas vraiment parlé de la nature orienté objet PROTOTYPALE de JS et je pense qu'on va juste pas le faire.
La classe doit hériter d'un composant HTML. Le plus simple est d'utiliser HTMLElement mais il est possible d'hériter, par ex., de HTMLDivElement ce qui sert normalement à étendre des éléments existents, aspect que je choisis de ne pas discuter dans cette section beaucoup trop longue.
Voilà le code pour my-app:
class MyApp extends HTMLElement {
constructor() {
super();
// Noter qu'il n'est pas obligatoire d'avoir un
// élément racine unique comme pour les trucs
// à base de Virtual DOM.
this.innerHTML = `
<h1>Ma super application illustrative</h1>
<progress-bar progress="0" />
`;
// Enregistrer une référence à la barre de prog.:
this.progressBar = this.querySelector('progress-bar');
// Initialiser la progression:
this.progress = 0;
}
connectedCallback() {
// Démarrer la progression factice:
const interval = setInterval(() => {
this.progress += 5;
(this.progress >= 100) && clearInterval(interval);
}, 300);
}
set progress(value) {
this._progress = value;
// Manuellement mettre à jour tout
// ce qui doit être réactif:
this.progressBar.setAttribute(
'progress',
this._progress
);
}
get progress() {
return this._progress;
}
}Voyons tout ça dans l'ordre: le constructeur d'abord. Puisqu'on hérite de quelque chose, appeler super() en premier est obligatoire. Vous devrez recopier cette ligne pour CHAQUE composant (si vous écrivez des composants React à l'ancienne, c'est pareil, vous vous souvenez que je disais que React était proche du JS natif?).
JavaScript.
Comme expliqué dans l'intro, le mot clé this permet de manipuler le DOM du composant à l'intérieur de la classe.
Un moment il faudra:
- Définir le contenu du composant;
- Déclarer des propriétés et/ou des éventuelles variables d'état (ben oui);
- Eventuellement faire d'autres trucs (désolé).
Pour définir le contenu du composant j'ai simplement utilisé innerHTML et un litéral qui est directement dans le constructeur:
this.innerHTML = `
<h1>Ma super application illustrative</h1>
<progress-bar progress="0" />
`;Il y a 100000 combinaisons différentes de manières et endroits pour définir le contenu du composant. Je vous montrerai au moins une autre manière avec le futur composant progress-bar mais on va pas trop s'attarder là dessus.
Je dirai simplement que vous n'êtes pas obligés de tout coller dans le code JS bien qu'à un moment ou l'autre, il faudra rappatrier le corps du composant dans le le script.
Un découpage bien propre en trois sections comme pour un composant Vue n'est pas possible sans créer votre propre abstraction. Ce qui n'est pas extrêmement compliqué en l'essence mais autant rester dans la jungle tant qu'on y est.
Beaucoup d'exemples en ligne créent d'abord un élément template puis assignent innerHTML sur cet élément. Reste encore à cloner récursivement le template dans le corps du composant. Je vous laisse le soin d'approfondir les recherches si ça vous intéresse.
Il parait qu'utiliser template c'est mieux parce que... Le contenu est déjà survolé et analysé ou un truc du genre. Je l'ai lu dans un commentaire dans un repo officiel de Chrome:
La création de ce tag template est parfois cachée derrière un GABARIT ETIQUETTE (MSDLKJHFLKDSJFH) mais je m'égare là où j'avais dit que j'allais pas m'égarer alors j'arrête.
J'ai choisi de conserver l'état global de mon application dans my-app pour coller aux exemples Vue et React, et je n'ai qu'une seule variable d'état: progress.
J'ai choisi de la mettre directement dans le composant et je vous le conseille aussi. Pour rappel, Vue accéde à ses variables d'état en utilisant this.variable. Je trouve que c'est plutôt bien, copions Vue.
Je récupère immédiatement l'élément progress-bar avec un bon vieux querySelector histoire d'en garder une référence interne (les frameworks utilisent parfois des refs à cette fin).
Prochaine étape: démarrer la progression fictive avec un setInterval. Cela n'a de sens que si le composant est monté dans le DOM donc j'utilise la méthode de cycle de vie connectedCallback:
connectedCallback() {
// Démarrer la progression factice:
const interval = setInterval(() => {
this.progress += 5;
(this.progress >= 100) && clearInterval(interval);
}, 300);
}J'incrémente simplement la propriété interne "progress" et j'arrête de compter une fois à 100. Remarquez que le composant progress-bar n'est pas mentionné mais ce serait bien que ça le mette à jour tout seul.
Vous savez, c'est cette histoire de programmation réactive. J'en ai parlé une ou deux fois et je disais que ce n'était pas prévu dans JS et les API du DOM. He ben vous savez quoi? C'est pas prévu dans les web components non plus.
On va devoir le prévoir nous-mêmes. Comme des vrais bricoleurs. Heureusement ça n'est pas très compliqué. Enfin je trouve.
On s'en doute, il existe plusieurs manières d'ajouter la réactivité. J'ai choisi d'utiliser des propriétés de classe, comme on voit ici:
set progress(value) {
this._progress = value;
// Manuellement mettre à jour tout
// ce qui doit être réactif:
this.progressBar.setAttribute(
'progress',
this._progress
);
}
get progress() {
return this._progress;
}C'est quoi cette affaire? Pour ceux qui ne sont pas familiers avec la notion de propriété de classe: nous avons un champ progress qui est accessible sur les instances de la classe, mais qui appelle en réalité des méthodes d'accès en arrière-plan.
Ces méthodes d'accès manipulent, dans notre cas, ce qu'on appelle communément un backing field (this._progress) qui devrait normalement être privé si JS avait de vrais modificateurs de visibilité ("BWEEEE DéKA, ça existe déjà!" — par "vrai" j'entends non considérés comme "expérimental").
J'aurais peut-être dû le dire comme ça: chaque fois qu'on utilise this.progress, ça appelle une des méthodes get ou set selon que l'on récupère ou modifie la valeur.
Il suffit alors de manuellement câbler tout ce qui doit être mis-à-jour dans le setter, d'où cette ligne:
this.progressBar.setAttribute(
'progress',
this._progress
);Pourquoi utiliser setAttribute et pas une propriété sur l'instance de ProgressBar? Bienvenue dans un élément de pourritude majeure des web components.
La méthode de cycle de vie qui permet de réagit en cas de changement d'attribut ne fonctionne... Qu'en cas de changement d'attribut. Tripoter this.progressBar.progress ça n'aura aucun effet, à moins que l'on ait écrit toute une plomberie dans ProgressBar pour avoir un get/set pour "progress" qui en interne appelle this.setAttribute et this.getAttribute.
Oui, c'est complexe. Une bonne pratique c'est juste de toujours utiliser getAttribute et setAttribute.
Une fois qu'une classe a été définie pour le composant il faut encore l'enregistrer pour qu'il soit utilisable dans le DOM, et lui donner un nom par la même occasion (en minuscule + au moins un tiret):
customElements.define('my-app', MyApp);Reste plus qu'à définir le composant ProgressBar et y cabler la logique pour réagir au changement d'attribut, parce que sinon il ne va rien se passer et ce serait dommage.
class ProgressBar extends HTMLElement {
// Il faut absolument utiliser les noms des props
// CSS avec tirets ici, ou ça va pas marcher.
baseStyle = {
'background-color': '#edebed',
height: '32px',
'box-shadow': '2px 2px 6px #fff',
width: '0%'
};
constructor() {
super();
}
connectedCallback() {
// Créons le div qui représente la barre
// de prog. manuellement cette fois-ci,
// et en dehors du constructeur pour changer (??)
this.container = document.createElement('div');
// Appliquer les styles de base:
this.container.style = generateStyleAttribute(this.baseStyle);
// Ajouter le div au DOM de l'élément:
this.appendChild(this.container);
}
// Pour pouvoir réagir à des changements d'attributs
// il faut absolument les mentionner de cette manière:
static get observedAttributes() {
return ['progress'];
}
// Ajouter manuellement la réactivité
// en réagissant aux changements d'attributs:
attributeChangedCallback(name, oldValue, newValue) {
// Comme le container n'est pas créé dans le
// constructeur, cette méthode sera appelée
// une première fois alors qu'il n'existe pas et
// génèrera une erreur, d'où mon check s'il existe:
if (this.container && name === 'progress') {
this.container.style.width =
newValue <= 100 ? `${newValue}%` : '100%';
}
}
}On commence par ajouter une propriété qui aurait dû être statique où je place un bon vieil object JS avec les CSS à mettre en ligne dedans, ce qui est un choix purement arbitraire parce que j'avais envie que ça ressemble à mon exemple React. Il aurait peut-être été plus propre d'ajouter un style global qui utilise le nom du composant et de tout mettre là. J'espère que vous sentez bien la liberté.
Cette fois-ci, pour changer, j'ai décidé de ne pas modifier le contenu de l'élément dans le constructeur, je le fais dans connectedCallback à la place.
Je pense (parce que vu que personne n'utilise des web components j'en sais rien) que la meilleure pratique est de générer le contenu dans connectedCallback.
La différence sera surtout apparente si de nombreux éléments sont créés dynamiquement par une boucle et ajoutés par après. La création appelle le constructeur uniquement, alors que l'ajout au DOM appelle connectedCallback. On répartit la tâche, quoi...
Cette fois-ci j'ai simplement créé un div avec document.createElement et l'ai ajouté au composant:
connectedCallback() {
// Créons le div qui représente la barre
// de prog. manuellement cette fois-ci,
// et en dehors du constructeur pour changer (??)
this.container = document.createElement('div');
// Appliquer les styles de base:
this.container.style = generateStyleAttribute(this.baseStyle);
// Ajouter le div au DOM de l'élément:
this.appendChild(this.container);
}Attends une minute mon ami! C'est quoi cette histoire de generateStyleAttribute?
Hah... Avec React ou Vue il est possible de donner un object JS comme attribut style et ça fonctionne tout seul, mais pas avec les web components tout nus. Tout simplement parce que la propriété style des composants s'attend à recevoir un string, pas un objet.
Par conséquent il faut écrire une méthode utilitaire infernale pour réaliser la transformation que j'ai copié-collée de je sais plus où (si vous captez rien au code c'est pas grave):
function generateStyleAttribute(styles) {
const allStyles = [];
for (let style in styles) {
if (styles.hasOwnProperty(style)) {
allStyles.push(`${style}: ${styles[style]}`);
}
}
return allStyles.join(';');
}Forcément avec 0Ko de dépendances il manque probablement deux ou trois trucs bien utiles qui sont inclus de base dans les frameworks. On a jamais rien sans rien. Non, vraiment, il y a rien du coup on a rien. Je me comprends.
Remarquez que je conserve une référence au div dans this.container.
Reste plus qu'à s'arranger pour que la barre de progression réagisse à l'attribut "progress", ce qui implique d'écrire la méthode attributeChangedCallback.
Pour ce que j'imagine être des raisons de performances, il est d'abord nécessaire de formellement déclarer les attributs qui doivent être observés sur le composants. Tout attribut non déclaré de cette manière ne déclenche pas la méthode attributeChangedCallback. D'où ce code:
static get observedAttributes() {
return ['progress'];
}La méthode attributeChangedCallback ne sera en pratique appelée que pour cet attribut, rendant le test "est-ce que name est progress?" inutile. Je l'ai mis parce que j'aime bien prévoir l'avenir.
attributeChangedCallback(name, oldValue, newValue) {
// Comme le container n'est pas créé dans le
// constructeur, cette méthode sera appelée
// une première fois alors qu'il n'existe pas et
// génèrera une erreur, d'où mon check s'il existe:
if (this.container && name === 'progress') {
this.container.style.width =
newValue <= 100 ? `${newValue}%` : '100%';
}
}Je prends simplement la nouvelle valeur de l'attribut et je l'utilise pour afficher la progression.
N'oublions pas d'enregistrer le composant:
customElements.define('progress-bar', ProgressBar);Résultat, pour un grand total de 3Ko de JS même pas minifié:
Comme "progress" est un réal attribut de l'élément (ce n'est pas obligatoire, l'attribut aurait pu être transformé en une variable interne et rester comme ça), les changements de valeurs opérés par JS sont vraiment visibles dans le DOM.
Voyez vous mêmes:
Il va se soi que si j'avais sérieusement l'intention de travailler avec des web components, je placerais chaque définition de classe dans son propre fichiers, idem pour la fonction utilitaire qui transforme l'objet JS en attribut "style", et je les importerais en utilisant les ES6 modules et/ou avec un module bundler comme Webpack/Parcel/Rollup.
Cet exemple est évidemment très limité, pas de shadow DOM, pas vraiment de manière unifiée de travailler avec des templates, et je ne vous ai pas du tout montré comment gérer des événements.
Et le style de programmation alors?
L'aspect déclaratif est assez clair, puisque les éléments sont inscrits directement dans le véritable DOM, leur hiérarchie est immédiatement apparente et des attributs peuvent également être fixés sur des valeurs initiales.
Pour les événements par contre c'est mois clair. Il est possible de les placer en attribut comme dans mon vieil exemple "déclaratif mais un peu foireux" qui traine 10000 pages plus haut mais ça demande d'écrire du câblage.
L'aspect réactif est absent, il faut l'implémenter soi-même. Ce qui n'est pas compliqué avec la méthode de cycle de vie attributeChangedCallback() (utilisé dans l'exemple) et les propriétés de classes basiques de JS mais représente une quantité significative de code de plomberie à écrire.
Comme d'habitude, il y a d'autres manières d'obtenir l'aspect réactif et tout un tas de nuances possibles.
L'aspect événementiel est directement prévu par le standard. Les web components peuvent recevoir leurs propres types d'événements et enregistrer des listeners à volonté sur leur structure interne et ont des méthodes de cycle de vie.
Un des gens de Google dont je parlais dans l'introduction a créé un site pour détecter les possibles problèmes d'incompatibilité entre le modèle d'événements utilisé par les frameworks/librairies et celui des web components.
Librairies pour web components
Les web components sont un standard. En terme de mise en oeuvre, ils manquent de rails de sécurité et euh... De chemin de fer. De trucs de guidage. Oui.
Dès le départ, les gens de Google ont publié cojointement une librairie qui "facilite" (je sais pas pourquoi je le mets entre guillements mais j'arrive pas à les effacer) la rédaction de web components et ajoute quelques trucs utile à l'API qui est un peu toute nue sinon.
Je pense qu'ils sont également les auteurs du polyfill pour le standard et le shadow DOM.
Ce projet s'appelait Polymer. Je parle au passé parce que la nature du projet a complètement changé.
Au départ l'idée était de fournir tous les outils pour réaliser une web application simple-page avec des web components.
La librairie ajoutait de quoi écrire facilement des bindings et donc prenait en charge l'aspect réactif comme n'importe quel framework JS le ferait, et, en plus, offrait une structure claire et déterminée pour écrire les composants qui ressemblait à Vue: une section template, une section style, une section script.
C'est d'ailleurs cette vieille version abandonnée de Polymer qui aurait influencé les auteurs de Vue à utiliser cette structure. Chouette histoire hein.
Polymer en tant que librairie qui pouvait effectivement remplacer tout un framework pour réaliser des applications mono-page est un peu tombé dans l'oubli.
Le projet qui est mis en avant depuis s'appelle LitElement, et ajoute une structure cohérente pour créer des web components, carrément avec des annotations pour les fans de TypeScript.
Pour essayer d'attirer plus de copains, ils ont été jusqu'au choix d'utiliser une méthode qui s'appelle render() pour sortir le contenu de l'élément. Il me semble avoir déjà vu ça quelque part...
Ils expliquent dans la description que la librairie permet de définir ses web components de manière totalement déclarative, et le tout est en plus réactif. Le rêve quoi.
Moi ça me fait un peu penser à JQuery pour les web components toute cette histoire, ce qui soulève certains signaux d'alarme. Pourquoi le standard n'a pas été écrit pour coller davantage à LitElement?
C'est trop tard maintenant.
LitElement ajoute à peu près 21Ko de JS, ce qui est (selon moi) raisonnable (dois-je rappeler que c'est sans polyfills?).
Ce qui me fait plus peur c'est l'horreur des changements de type "on casse tout et on recommence" qu'a subi Polymer au fil du temps.
La première version de ce blog était écrite avec Polymer 1.0. A l'époque ils essayaient de faire passer un standard aujourd'hui abandonné: les IMPORTS HTML, qui ressemblent un peu au mot clé import en JS mais c'était bien plus laid.
Un fichier composant typique pouvait commencer par ce genre de choses (oui, ils utilisaient bower aussi, je me fais insulter par npm à chaque fois pour ça):
<link rel="import" href="../../bower_components/polymer/polymer.html">
<link rel="import" href="../../bower_components/paper-material/paper-material.html">
<link rel="import" href="../../bower_components/paper-input/paper-input.html">
<link rel="import" href="../../bower_components/paper-input/paper-textarea.html">
<link rel="import" href="../../bower_components/paper-spinner/paper-spinner.html">
<link rel="import" href="../../bower_components/paper-button/paper-button.html">
<link rel="import" href="../../bower_components/iron-icons/iron-icons.html">
<link rel="import" href="../../bower_components/iron-ajax/iron-ajax.html">
<link rel="import" href="../../bower_components/iron-flex-layout/classes/iron-flex-layout.html">
<link rel="import" href="../../styles/shared-styles.html">Ces tags link de type "import" sont dépréciés et seront retirés dans l'avenir. Il ne fonctionneront plus que par l'intervention du polyfill. Autant vous dire que c'était globalement la grosse fête du polyfill et c'est sûrement pour ça que ça s'appelle Polymer (??).
J'aimais bien l'idée de pouvoir créer toute une mise-en-page responsive (qui s'adapte aux mobiles) avec menu de navigation à partir de quelques composants déjà faits, le tout avec apparence material design, non seulement sans connaissances du CSS requises, mais sans framework CSS en prime!
Pour le moi qui captait quedalle aux CSS c'était magique.

Chaque version majeure de Polymer a plus ou moins tout changé. Et bien qu'ils fournissent des outils de mise-à-jour, ça n'a jamais fonctionné pour moi.
Je pense qu'un moment ils ont compris que les web components n'étaient pas censés être utilisés comme un framework.
Premièrement, les frameworks existants sont bien plus populaires, et secondement, ils ont parfois des scripts qui permettent de générer des web components à partir de composants du framework, et les gens vont sûrement préférer ça qu'utiliser Polymer ou une librairie équivalente (il y en a d'autres je pense mais ça doit pas être la fête des statistiques d'usage non plus).
Le Shadow DOM
Je n'ai pas utilisé le Shadow DOM dans mes exemples par soucis de clarté et comme illustration supplémentaire de la souplesse des niveaux de choix qui vous est offerte par les web components.
Je peux vous décrire les avantages du Shadow DOM vite fait:
- Permet de définir un élément <style> dans le corps du composant qui sera limité à la portée du dit composant uniquement. Ceci est générallement suffisant pour que les gens qui ne sont pas moi adoptent le Shadow DOM;
- Limite la portée de la REMONTEE D'EVENEMENTS — Lié à cette vieille histoire de si j'ai un événement click sur un div et sur body et que je click sur le div, les deux événements vont être lancés.
La très grande majorité des exemples de web components à trouver sur les Internets utilisent le Shadow DOM et honnêtement, c'est plutôt difficile de faire sans dès que le composant devient un petit peu complexe au niveau des styles (à moins d'avoir tout un plan d'auto-génération de classes CSS globales uniques à la volée mais si vous utilisez ce genre de trucs je sais pas ce que vous faites ici, coucou!).
Bon alors comment ça marche ce shadow truc?
Au niveau de la classe (ou fonction, parce qu'une classe c'est secrètement une fonction en JS mais j'essayais de pas vous le dire mais trop tard alors essayez d'oublier que je l'ai dit) il s'agit d'abord d'appeler cette méthode:
this.attachShadow({mode: 'open'});C'est censé être dans le constructeur. Me demandez pas pourquoi, mettez le dans le constructeur. Merci.
Le composant présente désormais une nouvelle racine pour attacher des composants, le template etc. Qui est accessible en tant que this.shadowRoot.
Utiliser le shadow DOM permet d'ajouter un tag <style> dans votre template (je conseille de commencer par ça) qui définit les styles privés et locaux du composant, avec le sélecteur :host qui vous permet de sélectionner l'élément lui-même.
Le sélécteur :host est courant, particulièrement parce que les web components sont inline par défaut alors que la plupart des web components qui existent dans la nature sont block ou inline-block. Si vous avez rien compris c'est pas grave.
Un petit cas d'étude
Un aspect important des web components c'est qu'on peut leur donner du contenu (des noeuds HTML) dans le DOM, et ils peuvent décider de quoi en faire.Ce genre de choses:
<progress-bar>
<img src="some_spinner.gif">
</progress-bar>Sans Shadow DOM, le tag img serait simplement ajouté comme contenu du composant. Il commencerait avec déjà un enfant dans son DOM. Elle est bien cette phrase.
Avec Shadow DOM, le tag img est toujours là mais ne s'affichera pas. Il faut l'enficher quelque part, avec un slot.
Le concept n'est pas unique aux web components, Vue a des capacités similaires et React aussi (ça s'appelle props.children je crois — parce que c'est pas le genre de React de faire un truc qui ressemble au standard).
J'en parle parce que ça ouvre des cas d'utilisation intéressants pour les web components.
Je rappelle que si JS est désactivé ou que le script qui était censé enregistrer le web component ne s'est pas exécuté pour une raison ou une autre, le contenu qui était inséré dans le composant (comme le tag img dans l'extrait plus haut) s'affiche normalement, et le composant peut être stylé même s'il n'est pas enregistré comme web component.
Ceci peut-être utilisé pour créer des éléments progressifs qui ont un comportement enrichi quand JS est activé (et que les web components sont supportés) et un comportement limité mais (si possible) fonctionnel dans le cas contraire.Un cas d'utilisation intéressant des web components reste de réaliser des petits trucs réutilisables partout et qui soient simples à insérer directement dans du code HTML.
C'est avec le concours des slots qu'il est possible de créer toute une mise-en-page masquée derrière un seul web component. Le code pourrait par exemple ressembler à ceci:
<super-layout>
<header slot="header">
<h1>Titre du super site</h1>
</header>
<main slot="content">
<p>Contenu intéressant</p>
</main>
<footer slot="footer">
<a href="#">Mon Twitter</a>
</footer>
</super-layout>Ce qui est particulièrement déclaratif ne trouvez-vous pas?
Les éléments peuvent être assignés dans le template du composant au travers d'éléments <slot> nommés (ou utiliser un slot non-nommé qui est celui par défaut et contient tous les éléments assignés directement au corps du web component).
Tout ça et plus encore est bien expliqué sur cette page du MDN.
Je vous donne un autre exemple que je pourrais implémenter pour le présent blog (c'est dans mes projets depuis des années): ajouter un Lightbox pour mes images.
Je vais en trouver un qui existe déjà pour illustrer mon propos.
OK je suis revenu de Google, et, en fait, personne n'a écrit de web component lightbox moderne. J'ai juste trouvé deux vieux composants Polymer qui ne fonctionneront pas sans JS.
Je vais devoir le faire moi-même, sérieusement?
Bon bon, c'est parti. Je l'ai mis sur Github. Et publié sur npm.
Ce composant me permet d'écrire ce genre de code:
<img-lightbox>
<a href="petite_image.png" target="_blank">
<img src="grosse_image.png">
</a>
</img-lightbox>Et obtenir ce résultat si le web component a pu être enregistré:

Sinon, l'image s'affiche quand même normalement avec un lien fonctionnel vers la version complète.
Puis je sais pas pourquoi j'ai mis un gif et pas une demo live:
Je vais vous dire tout de suite que ce n'est pas du tout nécessaire d'en faire un web component, on aurait pu sélectionner les éléments image et lien avec un querySelectorAll et tripoter tout le bazar en ajoutant des styles etc. Il existe d'ailleurs déjà un paquet npm qui s'appelle img-lightbox et qui fait justement ça et à cause duquel j'ai du renommer le mien. Mais je suis pas deg.
Un des avantages du web component qui m'a été très utile, c'est de pouvoir placer des styles privés avec le Shadow DOM. Par exemple, ajouter des @keyframes pour une animation CSS "privée" est impossible sans Shadow DOM, ils doivent se trouver dans les styles globaux.
Il existe une fonction "animate" qui peut remplacer toutes les déclarations CSS mais c'est considéré comme "expérimental" dans le genre plus que les web components. Donc euh... C'est pas trop une solution pour l'instant.
Mon avis
Les web components se sont pas un framework ni une librairie. C'est un standard qui s'enchasse sur la plateforme DOM normale.
C'est à vous de définir votre manière de travailler, d'ajouter vos librairies éventuelles, de choisir ce qui sera réactif et comment ce sera implémenté, etc.
Pourquoi est-ce que j'en parle comme si c'était un framework? Ben je sais pas trop, c'est un peu le bordel cet article.
Il est tout à fait possible de créer un frontend complet qui utilise une hiérarchie de web components (c'était l'idée de base derrière Polymer).
Est-ce que c'est une bonne idée? Je ne suis pas sûr.
Déjà, chaque web component est un objet JavaScript avec probablement un état interne. Générer une liste de 10000 web components est potentiellement problématique en terme de mémoire et de temps d'exécution, alors qu'afficher un rendu de 10000 composants Vue... C'est potentiellement problématique aussi mais potentiellement moins. Je crois. Prout.
Je pense que le plus gros obstacle à "utiliser le web components comme si c'était un framework" c'est surtout qu'il existe déjà des frameworks et ils fonctionnent très bien mis à part leur coût en Kilobytes de JS.
Coût qui devient ridicule dans le cas de Svelte, par exemple (j'en parle plus loin).
En plus les API du DOM sont légèrement nazes, ce qui oblige d'inclure un peu de plomberie qui va aussi augmenter la taille du JS.
Là où les web components se déclinent, c'est pour réaliser de petits éléments réutilisables (éventuellement composables) qui fonctionneront sans compilation nécessaire et avec très peu de dépendance et dans pratiquement n'importe quelles conditions, lesquelles comprennent un usage au sein d'un framework JS, comme React.
Le même web component peut être partagé entre plusieurs applications qui utilisent des frameworks différents. Exemple plutôt réaliste: votre entreprise est obligée d'entretenir du vieux code moisi AngularJS 1.0 Official Killed By Google release et vous souhaitez déjà prévoir certaines pistes d'évolution qui seront réutilisables ultérieurement: vous pouvez y intégrer des web components.
Au niveau technologique je ne peux pas prédire si ce sera le futur ou non... A vue de nez ce n'est que très moyennement bien parti. Certains essayent de passer Web Assembly comme le futur. Moi tant que Flash ne revient pas je suis content.
De plus, j'utiliserai certainement, dans un avenir moyennement proche, une version du composant img-ligthbox que j'ai créé en écrivant le présent article. Chouette, hein.
Le web component du pauvre
Il sera toujours nativement possible de récupérer des éléments du DOM et leur appliquer des styles, modifier leur contenu et leur ajouter des écouteurs sur des événements.
En assemblant une massive soupe maléfique de projets depuis les module bundlers à des moteurs de templates, processeurs CSS et autres compilo-TypeScripto-machins il est possible de générer tout un site sur mesure.
A plus petite échelle, n'importe qui peut écrire une simple classe JS qui ajoute un template (qui peut même provenir d'un vrai tag template) à un endroit à définir et enregistre des événements. Puis voilà. C'est tout.
Il ne faut ni web component ni framework ni librairie ni polyfill mais le prix à payer est qu'il faut obligatoirement programmer en "impératif". Ce qui est détesté des masses, je le rappelle. Et pour un gros projet ça a du sens de ne pas être fan d'un machin dont la structure est un petit peu trop libre.
Je pourrais néanmoins refaire l'exemple de barre de progression beaucoup plus simplement, j'imagine qu'après tout le chemin qu'on a fait ensembles vous comprenez l'extrait suivant:
<div id="myApp"></div>
<script>
class MyApp {
constructor(element) {
element.innerHTML = `
<h1>Ma super application illustrative</h1>
`;
this.progressBar = document.createElement('div');
this.progressBar.style.backgroundColor = '#edebed';
this.progressBar.style.height = '32px';
this.progressBar.style.boxShadow = '2px 2px 6px #fff';
this.progress = 0;
element.appendChild(this.progressBar);
this.start();
}
set progress(value) {
this._progress = value;
this.progressBar.style.width = value + '%';
}
get progress() {
return this._progress;
}
start() {
const interval = setInterval(() => {
this.progress += 5;
(this.progress >= 100) && clearInterval(interval);
}, 300);
}
}
const myApp = new MyApp(document.getElementById('myApp'));
</script>C'est tout comme si on montait un framework sur l'élément avec l'ID "myApp". Mais en fait non, c'est un gros truc de pauvre. Non pas qu'il y ait de mal à être pauvre, c'est plutôt signe de bonnes performances en JS être pauvre.
Je vous avais dit qu'on avait abandonné le déclaratif, mais pas à 100%, c'est toujours relativement clair qu'il va se passer quelque chose dans cet élément avec l'ID "myApp". Ce qui est directement visible s'arrête là.
Je sais pourquoi je montre chaque fois le truc vu que c'est le même résultat et que non seulement on s'en fout mais qu'en plus je pourrais vous vendre des sacs:
Les petits malins parmis les deux lecteurs arrivés jusqu'ici auront peut-être remarqué qu'il n'y a plus vraiment de "composant" ProgressBar. Il y a juste MyApp.
La composabilité est un petit peu tombé à l'eau comme le type à la fin de Titanic.
C'est possible de l'ajouter, on se rapproche alors dangeureusement de la situation qui vérifie la citation "à travailler sans framework on finit par créer son propre framework".
Reste aussi que sans Shadow DOM (qui par ailleurs fonctionne indépendamment des web components) c'est assez vite l'enfer au niveau CSS, à moins d'être à l'aise avec les styles globaux (peut-être en utilisant des noms de classe générés?).
Svelte
Svelte sera le dernier "framework" (c'est encore une librairie en fait voire euh... Un langage, que l'auteur il dit **météorisme**) que j'aborde dans cet article et celui que je considère comme le meilleur choix hors contraintes exceptionnelles.
Vous le saviez déjà parce que vous aviez lu cette brève n'est-il pas?
L'auteur de Svelte livre une intense abondance de commentaires sur à quel point le Virtual DOM c'est pourri. Vous aurez peut-être compris que je n'en suis pas fan non plus mais même moi je n'irais pas aussi loin dans l'insistance.
Svelte recycle la bonne idée de Vue de compiler les composants à partir de fichiers qui séparent bien proprement les CSS, le template, et le JavaScript.
C'est même encore plus épuré que Vue, avec l'idée d'accomplir le maximum par compilation, là où Vue a toujours des racines natives puisque la librairie peut fonctionner sans compilation.
Je vous invite à aller jeter un coup d'oeil sur le site officiel, il y a même un REPL qui vous permet d'immédiatement expérimenter.
Dois-je préciser que c'est déclaratif et réactif? Et tout ça sans Virtual DOM et avec un poids additionnel minimal en terme de JS?
Un petit exemple?
Bon c'est bien parce que c'est vous, on va se taper une petite barre de progression pour finir en beauté.
Je reprends une structure à base de <App /> qui possède un bon vieux composant <ProgressBar >, voici <App /> (le composant racine):
<script>
import ProgressBar from './ProgressBar.svelte';
let progress = 0;
const interval = setInterval(() => {
progress += 5;
(progress >= 100) && clearInterval(interval);
}, 300);
</script>
<main>
<h1>Ma super application illustrative</h1>
<ProgressBar progress="{progress}" />
</main>Pour ce qui est de la génération artificielle de la progression avec setInterval il n'y a aucune farce comme avec React, ça fonctionne même en dehors d'une méthode de cycle de vie.
Ce composant n'a pas de section style. Remarquez que les variables locales sont disponibles pour des bindings dans le template.
Ces variables sont l'équivalent des variables d'état des autres exemples. C'est une manière élégante et simple de le présenter je trouve.
Pour que ces variables locales deviennent modifiables depuis des composants parents (et deviennent dès lors des attributs), il faut les précéder de export comme nous le verrons avec le composant suivant.
<script>
export let progress = 0;
</script>
<div style="width: {progress}%"></div>
<style>
div {
background-color: #edebed;
height: 32px;
box-shadow: 2px 2px 6px #fff;
width: 0%;
}
</style>Vous avez vu comme c'est simple de fixer l'attribut style comme réactif en composition avec une variable qui est exportée en tant qu'attribut du composant?
C'est encore plus clair qu'un composant Vue tout en tenant sur moins de lignes!
Je vous montre une dernière fois le résultat parce que je suis trop psychorigide pour ne pas le faire. Le tout pour environ 3.5Ko de JS minifié, soit un petit peu plus que pour mon exemple à base de web components (qui n'était pas minifié).
Conclusion
Je sais pas si c'était évident ou non mais j'aime bien Svelte. C'est léger, ça a du sens, et de toutes façons dès qu'on veut faire un truc un peu sérieux en JS il faut compiler des trucs.
Un point négatif: l'écosystème est significativement moins touffu que celui des autres géants précités (pas d'option pour le dev natif mobile, par ex.) et le support TypeScript existe mais demande une certaine expertise de Webpack ou Rollup.
Je me permet tout de même de citer Sapper qui permet de fabriquer des applications hybrides mono-page et générées côté serveur et moi, ça me suffit.
Bon on pourrait aussi ajouter que l'auteur de la librairie est légèrement arrogant là où les autres géants sont générallement assez humbles.
A lire ce qu'il écrit ou raconte on dirait que genre... Ajouter l'aspect réactif sur base de variables d'état n'a aucune conséquence en terme de performances. Ce qui est un gros sac qu'un bon businessman essayerait de vous vendre. Je m'y attends pas trop de la part d'un des experts JS du oueb.
Oui l'impact est moindre qu'avec un virtual DOM, mais il y a un impact.
Il a aussi clashé les web components dans un post avec toute une liste d'arguments (10 ou 12) et je ne suis d'accord qu'avec 2 ou max 3 d'entre eux. Sachant qu'un des arguments est LE DOM C'EST NUL lol.
Je vous mentirais si je disais pas que ça m'inquiète un peu mais le nombre de frameworks JS qui ajoutent moins de 50Kb de JS est proche de zéro. Et alors le Virtual DOM ça reste toujours légèrement nul.
Ce sont ces raisons qui m'ont poussé à présenter Svelte alors qu'il est souvent exclu du club des frameworks connus.
Conclusion
He ben dites donc les enfants. Tout ça pour parler de quatre frameworks, un standard et du code moche.
Au départ je voulais juste souligner au saindoux que tout le monde et sa soeur veulent absolument programmer déclarativement, et avec un aspect réactif réflexif instantané (oui j'ai totalement inventé cette suite de mots).
Malheureusement, le standard JavaScript actual ne le permet pas. Résultat, les gens écrivent des librairies qui le permettent, soit au travers de couches supplémentaires avant le rendu final dans le DOM du navigateur (par ex. notre ami le Virtual DOM) soit par compilation en code qui prend en charge l'aspect réactif au cas par cas (plus ou moins).
Tout ça entraîne indubitablement une baisse de performances.
D'ailleurs, je ne souhaite briser les espoirs de personne, mais implémenter des bindings et autre mécanismes réactifs nativement ça n'est jamais gratuit non plus et comme souvent, ce seront les plus démunis (entendre "ceux qui ont un téléphone tout naze d'il y a 10 4 ans") qui vont souffir le plus.
C'est pas pour rien que les bindings en JavaFX utilisent beaucoup de CPU et qu'ils ont fait le choix de mettre en place des stratégies de mise à jour conservatrices en XAML pour WPF et Xamarin (plateforme .NET) - où il faut manuellement ajouter des trucs et des machins pour avoir la réactivité complète d'une interface. Les concepteurs sont au courant que ça ralentit tout.
J'imagine qu'un jour ou l'autre, des aspects réactifs vont apparaître dans la plateforme. Je n'en ai pas du tout parlé dans cet article mais il me semble que la notion d'Observable utilisée par la librairie RxJS est en proposition depuis perpet pour entrer dans le standard.
On pourrait tout autant se dire que ce n'est pas nécessaire dans le standard. Nos super copains les frameworks existent et maintenant tout le monde a appris React ou Vue, tu vas pas faire chier avec encore un autre truc hein??
Moi tant que vous restez frais, avec du code facilement testable qui produit quelque chose d'accessible et de vaguement présentable si JS est désactivé, je suis toujours content.
Commentaires
Il faut JavaScript activé pour écrire des commentaires ici